This is the multi-page printable view of this section. Click here to print.
Administrasi Klaster
- 1: Ikhtisar Administrasi Klaster
- 2: Sertifikat
- 3: Penyedia Layanan Cloud
- 4: Mengelola Resource
- 5: Jaringan Kluster
- 6: Arsitektur Logging
- 7: Metrik untuk Komponen Sistem Kubernetes
- 8: Konfigurasi Garbage Collection pada kubelet
- 9: Berbagai Proxy di Kubernetes
- 10: Metrik controller manager
- 11: Instalasi Add-ons
- 12: Prioritas dan Kesetaraan API (API Priority and Fairness)
1 - Ikhtisar Administrasi Klaster
Ikhtisar administrasi klaster ini ditujukan untuk siapapun yang akan membuat atau mengelola klaster Kubernetes. Diharapkan untuk memahami beberapa konsep dasar Kubernetes sebelumnya.
Perencanaan Klaster
Lihat panduan di Persiapan untuk mempelajari beberapa contoh tentang bagaimana merencanakan, mengatur dan mengonfigurasi klaster Kubernetes. Solusi yang akan dipaparkan di bawah ini disebut distro.
Sebelum memilih panduan, berikut adalah beberapa hal yang perlu dipertimbangkan:
- Apakah kamu hanya ingin mencoba Kubernetes pada komputermu, atau kamu ingin membuat sebuah klaster dengan high-availability, multi-node? Pilihlah distro yang paling sesuai dengan kebutuhanmu.
- Jika kamu merencanakan klaster dengan high-availability, pelajari bagaimana cara mengonfigurasi klaster pada multiple zone.
- Apakah kamu akan menggunakan Kubernetes klaster di hosting, seperti Google Kubernetes Engine, atau hosting sendiri klastermu?
- Apakah klastermu berada pada on-premises, atau di cloud (IaaS)? Kubernetes belum mendukung secara langsung klaster hibrid. Sebagai gantinya, kamu dapat membuat beberapa klaster.
- Jika kamu ingin mengonfigurasi Kubernetes on-premises, pertimbangkan model jaringan yang paling sesuai.
- Apakah kamu ingin menjalankan Kubernetes pada "bare metal" hardware atau pada virtual machines (VM)?
- Apakah kamu hanya ingin mencoba klaster Kubernetes, atau kamu ingin ikut aktif melakukan pengembangan kode dari proyek Kubernetes? Jika jawabannya yang terakhir, pilihlah distro yang aktif dikembangkan. Beberapa distro hanya menggunakan rilis binary, namun menawarkan lebih banyak variasi pilihan.
- Pastikan kamu paham dan terbiasa dengan beberapa komponen yang dibutuhkan untuk menjalankan sebuah klaster.
Catatan: Tidak semua distro aktif dikelola. Pilihlah distro yang telah diuji dengan versi terkini dari Kubernetes.
Mengelola Klaster
-
Mengelola klaster akan menjabarkan beberapa topik terkait lifecycle dari klaster: membuat klaster baru, melakukan upgrade pada node master dan worker, melakukan pemeliharaan node (contoh: upgrade kernel), dan melakukan upgrade versi Kubernetes API pada klaster yang sedang berjalan.
-
Pelajari bagaimana cara mengatur node.
-
Pelajari bagaimana cara membuat dan mengatur kuota resource (resource quota) untuk shared klaster.
Mengamankan Klaster
-
Sertifikat (certificate) akan menjabarkan langkah-langkah untuk membuat sertifikat menggunakan beberapa tool chains.
-
Kubernetes Container Environment akan menjelaskan environment untuk kontainer yang dikelola oleh Kubelet pada Kubernetes node.
-
Mengontrol Akses ke Kubernetes API akan menjabarkan bagaimana cara mengatur izin (permission) untuk akun pengguna dan service account.
-
Autentikasi akan menjelaskan autentikasi di Kubernetes, termasuk ragam pilihan autentikasi.
-
Otorisasi dibedakan dari autentikasi, digunakan untuk mengontrol bagaimana HTTP call ditangani.
-
Menggunakan Admission Controllers akan menjelaskan plug-in yang akan melakukan intersep permintaan sebelum menuju ke server Kubernetes API, setelah autentikasi dan otorisasi dilakukan.
-
Menggunakan Sysctls pada Klaster Kubernetes akan menjabarkan tentang cara menggunakan perintah
sysctlpada command-line untuk mengatur parameter kernel. -
Audit akan menjelaskan bagaimana cara berinteraksi dengan log audit Kubernetes.
Mengamankan Kubelet
Layanan Tambahan Klaster
-
Integrasi DNS akan menjelaskan bagaimana cara resolve suatu nama DNS langsung pada service Kubernetes.
-
Logging dan Monitoring Aktivitas Klaster akan menjelaskan bagaimana cara logging bekerja di Kubernetes serta bagaimana cara mengimplementasikannya.
2 - Sertifikat
Saat menggunakan autentikasi sertifikat klien, kamu dapat membuat sertifikat
secara manual melalui easyrsa, openssl atau cfssl.
easyrsa
easyrsa dapat digunakan untuk menghasilkan sertifikat klaster kamu secara manual.
-
Unduh, buka paket, dan inisialisasi versi tambal easyrsa3.
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pki -
Hasilkan CA. (
--batchuntuk atur mode otomatis.--req-cnuntuk menggunakan default CN.)./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass -
Hasilkan sertifikat dan kunci server. Argumen
--subject-alt-namedigunakan untuk mengatur alamat IP dan nama DNS yang dapat diakses oleh server API.MASTER_CLUSTER_IPbiasanya merupakan IP pertama dari CIDR service cluster yang diset dengan argumen--service-cluster-ip-rangeuntuk server API dan komponen manajer pengontrol. Argumen--daysdigunakan untuk mengatur jumlah hari masa berlaku sertifikat. Sampel di bawah ini juga mengasumsikan bahwa kamu menggunakancluster.localsebagai nama domain DNS default../easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopass -
Salin
pki/ca.crt,pki/issued/server.crt, danpki/private/server.keyke direktori kamu. -
Isi dan tambahkan parameter berikut ke dalam parameter mulai server API:
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
openssl secara manual dapat menghasilkan sertifikat untuk klaster kamu.
-
Hasilkan ca.key dengan 2048bit:
openssl genrsa -out ca.key 2048 -
Hasilkan ca.crt berdasarkan ca.key (gunakan -days untuk mengatur waktu efektif sertifikat):
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt -
Hasilkan server.key dengan 2048bit:
openssl genrsa -out server.key 2048 -
Buat file konfigurasi untuk menghasilkan Certificate Signing Request (CSR). Pastikan untuk mengganti nilai yang ditandai dengan kurung sudut (mis.
<MASTER_IP>) dengan nilai sebenarnya sebelum menyimpan ke file (mis.csr.conf). Perhatikan bahwa nilaiMASTER_CLUSTER_IPadalah layanan IP klaster untuk server API seperti yang dijelaskan dalam subbagian sebelumnya. Sampel di bawah ini juga mengasumsikan bahwa kamu menggunakancluster.localsebagai nama domain DNS default.[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
Hasilkan permintaan penandatanganan sertifikat berdasarkan file konfigurasi:
openssl req -new -key server.key -out server.csr -config csr.conf -
Hasilkan sertifikat server menggunakan ca.key, ca.crt dan server.csr:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -sha256 -
Lihat sertifikat:
openssl x509 -noout -text -in ./server.crt
Terakhir, tambahkan parameter yang sama ke dalam parameter mulai server API.
cfssl
cfssl adalah alat lain untuk pembuatan sertifikat.
-
Unduh, buka paket dan siapkan command line tools seperti yang ditunjukkan di bawah ini. Perhatikan bahwa kamu mungkin perlu menyesuaikan contoh perintah berdasarkan arsitektur perangkat keras dan versi cfssl yang kamu gunakan.
curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o cfssl chmod +x cfssl curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o cfssljson chmod +x cfssljson curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
Buat direktori untuk menyimpan artifacts dan inisialisasi cfssl:
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
Buat file konfigurasi JSON untuk menghasilkan file CA, misalnya,
ca-config.json:{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
Buat file konfigurasi JSON untuk CA certificate signing request (CSR), misalnya,
ca-csr.json. Pastikan untuk mengganti nilai yang ditandai dengan kurung sudut dengan nilai sebenarnya yang ingin kamu gunakan.{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
Hasilkan kunci CA (
ca-key.pem) dan sertifikat (ca.pem):../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
Buat file konfigurasi JSON untuk menghasilkan kunci dan sertifikat untuk API server, misalnya,
server-csr.json. Pastikan untuk mengganti nilai dalam kurung sudut dengan nilai sebenarnya yang ingin kamu gunakan.MASTER_CLUSTER_IPadalah layanan klaster IP untuk server API seperti yang dijelaskan dalam subbagian sebelumnya. Sampel di bawah ini juga mengasumsikan bahwa kamu menggunakancluster.localsebagai nama domain DNS default.{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
Buat kunci dan sertifikat untuk server API, yang mana awalnya di simpan masing-masing ke dalam file
server-key.pemdanserver.pem:../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
Distribusi Sertifikat Self-Signed CA
Node klien dapat menolak untuk mengakui sertifikat CA yang ditandatangani sendiri sebagai valid. Untuk deployment non-produksi, atau untuk deployment yang berjalan di belakang firewall perusahaan, kamu dapat mendistribusikan sertifikat CA yang ditandatangani sendiri untuk semua klien dan refresh daftar lokal untuk sertifikat yang valid.
Pada setiap klien, lakukan operasi berikut:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
Sertifikat API
Kamu dapat menggunakan API Certificate.k8s.io untuk menyediakan
sertifikat x509 yang digunakan untuk autentikasi seperti yang didokumentasikan
di sini.
3 - Penyedia Layanan Cloud
Laman ini akan menjelaskan bagaimana cara mengelola Kubernetes yang berjalan pada penyedia layanan cloud tertentu.
Kubeadm
Kubeadm merupakan salah satu cara yang banyak digunakan untuk membuat klaster Kubernetes. Kubeadm memiliki beragam opsi untuk mengatur konfigurasi spesifik untuk penyedia layanan cloud. Salah satu contoh yang biasa digunakan pada penyedia cloud in-tree yang dapat diatur dengan kubeadm adalah sebagai berikut:
apiVersion: kubeadm.k8s.io/v1beta1
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
cloud-provider: "openstack"
cloud-config: "/etc/kubernetes/cloud.conf"
---
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.13.0
apiServer:
extraArgs:
cloud-provider: "openstack"
cloud-config: "/etc/kubernetes/cloud.conf"
extraVolumes:
- name: cloud
hostPath: "/etc/kubernetes/cloud.conf"
mountPath: "/etc/kubernetes/cloud.conf"
controllerManager:
extraArgs:
cloud-provider: "openstack"
cloud-config: "/etc/kubernetes/cloud.conf"
extraVolumes:
- name: cloud
hostPath: "/etc/kubernetes/cloud.conf"
mountPath: "/etc/kubernetes/cloud.conf"
Penyedia layanan cloud in-tree biasanya membutuhkan --cloud-provider dan --cloud-config yang ditentukan sebelumnya pada command lines untuk kube-apiserver, kube-controller-manager dan
kubelet. Konten dari file yang ditentukan pada --cloud-config untuk setiap provider akan dijabarkan di bawah ini.
Untuk semua penyedia layanan cloud eksternal, silakan ikuti instruksi pada repositori masing-masing penyedia layanan.
AWS
Bagian ini akan menjelaskan semua konfigurasi yang dapat diatur saat menjalankan Kubernetes pada Amazon Web Services.
Nama Node
Penyedia layanan cloud AWS menggunakan nama DNS privat dari instance AWS sebagai nama dari objek Kubernetes Node.
Load Balancer
Kamu dapat mengatur load balancers eksternal sehingga dapat menggunakan fitur khusus AWS dengan mengatur anotasi seperti di bawah ini.
apiVersion: v1
kind: Service
metadata:
name: example
namespace: kube-system
labels:
run: example
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: arn:aws:acm:xx-xxxx-x:xxxxxxxxx:xxxxxxx/xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx #ganti nilai ini
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: http
spec:
type: LoadBalancer
ports:
- port: 443
targetPort: 5556
protocol: TCP
selector:
app: example
Pengaturan lainnya juga dapat diaplikasikan pada layanan load balancer di AWS dengan menggunakan anotasi-anotasi. Berikut ini akan dijelaskan anotasi yang didukung oleh AWS ELB:
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval: Digunakan untuk menentukan interval pengeluaran log akses.service.beta.kubernetes.io/aws-load-balancer-access-log-enabled: Digunakan untuk mengaktifkan atau menonaktifkan log akses.service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name: Digunakan untuk menentukan nama bucket S3 log akses.service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix: Digunakan untuk menentukan prefix bucket S3 log akses.service.beta.kubernetes.io/aws-load-balancer-additional-resource-tags: Digunakan untuk menentukan daftar tag tambahan pada ELB dengan menggunakan parameter key-value. Contoh:"Key1=Val1,Key2=Val2,KeyNoVal1=,KeyNoVal2".service.beta.kubernetes.io/aws-load-balancer-backend-protocol: Digunakan untuk menentukan protokol yang digunakan oleh backend (pod) di belakang listener. Jika diset kehttp(default) atauhttps, maka akan dibuat HTTPS listener yang akan mengakhiri koneksi dan meneruskan header. Jika diset kesslatautcp, maka akan digunakan "raw" SSL listener. Jika diset kehttpdanaws-load-balancer-ssl-certtidak digunakan, maka akan digunakan HTTP listener.service.beta.kubernetes.io/aws-load-balancer-ssl-cert: Digunakan untuk meminta secure listener. Nilai yang dimasukkan adalah sertifikat ARN yang valid. Info lebih lanjut lihat ELB Listener Config CertARN merupakan IAM atau CM certificate ARN, contoh:arn:aws:acm:us-east-1:123456789012:certificate/12345678-1234-1234-1234-123456789012.service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabled: Digunakan untuk mengaktifkan atau menonaktfkan connection draining.service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeout: Digunakan untuk menentukan connection draining timeout.service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout: Digunakan untuk menentukan idle connection timeout.service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: Digunakan untuk mengaktifkan atau menonaktifkan cross-zone load balancing.service.beta.kubernetes.io/aws-load-balancer-extra-security-groups: Digunakan untuk menentukan grup keamanan yang akan ditambahkan pada ELB yang dibuat.service.beta.kubernetes.io/aws-load-balancer-internal: Digunakan sebagai indikasi untuk menggunakan internal ELB.service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: Digunakan untuk mengaktifkan proxy protocol pada ELB. Saat ini hanya dapat menerima nilai*yang berarti mengaktifkan proxy protocol pada semua ELB backends. Di masa mendatang kamu juga dapat mengatur agar proxy protocol hanya aktif pada backends tertentu..service.beta.kubernetes.io/aws-load-balancer-ssl-ports: Digunakan untuk menentukan daftar port--yang dipisahkan koma-- yang akan menggunakan SSL/HTTPS listeners. Nilai default yaitu*(semua).
Informasi anotasi untuk AWS di atas diperoleh dari komentar pada aws.go
Azure
Nama Node
Penyedia layanan cloud Azure menggunakan hostname dari node (yang ditentukan oleh kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan nama Azure VM.
CloudStack
Nama Node
Penyedia layanan cloud CloudStack menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan nama Cloudstack VM.
GCE
Nama Node
Penyedia layanan cloud GCE menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa segmen pertama dari nama Kubernetes Node harus sesuai dengan nama instance GCE (contoh: sebuah node dengan nama kubernetes-node-2.c.my-proj.internal harus sesuai dengan instance yang memiliki nama kubernetes-node-2).
OpenStack
Bagian ini akan menjelaskan semua konfigurasi yang dapat diatur saat menggunakan OpenStack dengan Kubernetes.
Nama Node
Penyedia layanan cloud OpenStack menggunakan nama instance (yang diperoleh dari metadata OpenStack) sebagai nama objek Kubernetes Node. Perlu diperhatikan bahwa nama instance harus berupa nama Kubernetes Node yang valid agar kubelet dapat mendaftarkan objek Node-nya.
Layanan
Penyedia layanan cloud OpenStack menggunakan beragam layanan OpenStack yang tersedia sebagai underlying cloud agar dapat mendukung Kubernetes:
| Layanan | Versi API | Wajib |
|---|---|---|
| Block Storage (Cinder) | V1†, V2, V3 | Tidak |
| Compute (Nova) | V2 | Tidak |
| Identity (Keystone) | V2‡, V3 | Ya |
| Load Balancing (Neutron) | V1§, V2 | Tidak |
| Load Balancing (Octavia) | V2 | Tidak |
† Block Storage V1 API tidak lagi didukung, dukungan Block Storage V3 API telah ditambahkan pada Kubernetes 1.9.
‡ Identity V2 API tidak lagi didukung dan akan dihapus oleh penyedia layanan pada rilis mendatang. Pada rilis "Queens", OpenStack tidak lagi mengekspos Identity V2 API.
§ Dukungan Load Balancing V1 API telah dihapus pada Kubernetes 1.9.
Service discovery dilakukan dengan menggunakan katalog layanan/servis (service catalog) yang diatur oleh
OpenStack Identity (Keystone) menggunakan auth-url yang ditentukan pada konfigurasi
penyedia layanan. Penyedia layanan akan menurunkan fungsionalitas secara perlahan saat layanan OpenStack selain Keystone tidak tersedia dan akan menolak dukungan fitur yang terdampak. Beberapa fitur tertentu dapat diaktifkan atau dinonaktfikan tergantung dari ekstensi yang diekspos oleh Neutron pada underlying cloud.
cloud.conf
Kubernetes berinteraksi dengan OpenStack melalui file cloud.conf. File ini akan menyuplai Kubernetes dengan kredensial dan lokasi dari Openstack auth endpoint. Kamu dapat membuat file cloud.conf dengan menambahkan rincian berikut ini di dalam file:
Konfigurasi pada umumnya
Berikut ini merupakan contoh dan konfigurasi yang biasa digunakan dan akan mencakup semua pilihan yang paling sering dibutuhkan. File ini akan merujuk pada endpoint dari Keystone OpenStack, serta menyediakan rincian bagaimana cara mengautentikasi dengannya, termasuk cara mengatur load balancer:
[Global]
username=user
password=pass
auth-url=https://<keystone_ip>/identity/v3
tenant-id=c869168a828847f39f7f06edd7305637
domain-id=2a73b8f597c04551a0fdc8e95544be8a
[LoadBalancer]
subnet-id=6937f8fa-858d-4bc9-a3a5-18d2c957166a
Global
Konfigurasi untuk penyedia layanan OpenStack berikut ini akan membahas bagian konfigurasi global sehingga harus berada pada bagian [Global] dari file cloud.conf:
auth-url(Wajib): URL dari API keystone digunakan untuk autentikasi. ULR ini dapat ditemukan pada bagian Access dan Security > API Access > Credentials di laman panel kontrol OpenStack.username(Wajib): Merujuk pada username yang dikelola keystone.password(Wajib): Merujuk pada kata sandi yang dikelola keystone.tenant-id(Wajib): Digunakan untuk menentukan id dari project tempat kamu membuat resources.tenant-name(Opsional): Digunakan untuk menentukan nama dari project tempat kamu ingin membuat resources.trust-id(Opsional): Digunakan untuk menentukan identifier of the trust untuk digunakan sebagai otorisasi. Suatu trust merepresentasikan otorisasi dari suatu pengguna (the trustor) untuk didelegasikan pada pengguna lain (the trustee), dan dapat digunakan oleh trustee berperan sebagai the trustor. Trust yang tersedia dapat ditemukan pada endpoint/v3/OS-TRUST/trustsdari Keystone API.domain-id(Opsional): Digunakan untuk menentukan id dari domain tempat user kamu berada.domain-name(Opsional): Digunakan untuk menentukan nama dari domain tempat user kamu berada.region(Opsional): Digunakan untuk menentukan identifier dari region saat digunakan pada multi-region OpenStack cloud. Sebuah region merupakan pembagian secara umum dari deployment OpenStack. Meskipun region tidak wajib berkorelasi secara geografis, suatu deployment dapat menggunakan nama geografis sebagai region identifier sepertius-east. Daftar region yang tersedia dapat ditemukan pada endpoint/v3/regionsdari Keystone API.ca-file(Optional): Digunakan untuk menentukan path dari file custom CA.
Saat menggunakan Keystone V3 - yang mengganti istilah tenant menjadi project - nilai tenant-id
akan secara otomatis dipetakan pada project yang sesuai di API.
Load Balancer
Konfigurasi berikut ini digunakan untuk mengatur load
balancer dan harus berada pada bagian [LoadBalancer] dari file cloud.conf:
lb-version(Opsional): Digunakan untuk menonaktifkan pendeteksian versi otomatis. Nilai yang valid yaituv1atauv2. Jika tidak ditentukan, maka pendeteksian otomatis akan memilih versi tertinggi yang didukung dari underlying OpenStack cloud.use-octavia(Opsional): Digunakan untuk menentukan apakah akan menggunakan endpoint dari layanan Octavia LBaaS. Nilai yang valid yaitutrueataufalse. Jika diset nilaitruenamun Octavia LBaaS V2 tidak dapat ditemukan, maka load balancer akan kembali menggunakan endpoint dari Neutron LBaaS V2. Nilai default adalahfalse.subnet-id(Opsional): Digunakan untuk menentukan id dari subnet yang ingin kamu buat load balancer di dalamnya. Nilai id ini dapat dilihat pada Network > Networks. Klik pada jaringan yang sesuai untuk melihat subnet di dalamnya.floating-network-id(Opsional): Jika diset, maka akan membuat floating IP untuk load balancer.lb-method(Opsional): Digunakan untuk menentukan algoritma pendistribusian yang akan digunakan. Nilai yang valid yaituROUND_ROBIN,LEAST_CONNECTIONS, atauSOURCE_IP. Jika tidak diset, maka akan menggunakan algoritma default yaituROUND_ROBIN.lb-provider(Opsional): Digunakan untuk menentukan penyedia dari load balancer. Jika tidak ditentukan, maka akan menggunakan penyedia default yang ditentukan pada Neutron.create-monitor(Opsional): Digunakan untuk menentukan apakah akan membuat atau tidak monitor kesehatan untuk Neutron load balancer. Nilai yang valid yaitutruedanfalse. Nilai default adalahfalse. Jika diset nilaitruemakamonitor-delay,monitor-timeout, danmonitor-max-retriesjuga harus diset.monitor-delay(Opsional): Waktu antara pengiriman probes ke anggota dari load balancer. Mohon pastikan kamu memasukkan waktu yang valid. Nilai waktu yang valid yaitu "ns", "us" (atau "µs"), "ms", "s", "m", "h"monitor-timeout(Opsional): Waktu maksimum dari monitor untuk menunggu balasan ping sebelum timeout. Nilai ini harus lebih kecil dari nilai delay. Mohon pastikan kamu memasukkan waktu yang valid. Nilai waktu yang valid yaitu "ns", "us" (atau "µs"), "ms", "s", "m", "h"monitor-max-retries(Opsional): Jumlah gagal ping yang diizinkan sebelum mengubah status anggota load balancer menjadi INACTIVE. Harus berupa angka antara 1 dan 10.manage-security-groups(Opsional): Digunakan untuk menentukan apakah load balancer akan mengelola aturan grup keamanan sendiri atau tidak. Nilai yang valid adalahtruedanfalse. Nilai default adalahfalse. Saat diset ketruemaka nilainode-security-groupjuga harus ditentukan.node-security-group(Opsional): ID dari grup keamanan yang akan dikelola.
Block Storage
Konfigurasi untuk penyedia layanan OpenStack berikut ini digunakan untuk mengatur penyimpanan blok atau block storage
dan harus berada pada bagian [BlockStorage] dari file cloud.conf:
bs-version(Opsional): Digunakan untuk menonaktifkan fitur deteksi versi otomatis. Nilai yang valid yaituv1,v2,v3danauto. Jika diset keautomaka pendeteksian versi otomatis akan memilih versi tertinggi yang didukung oleh underlying OpenStack cloud. Nilai default jika tidak diset adalahauto.trust-device-path(Opsional): Pada umumnya nama block device yang ditentukan oleh Cinder (contoh:/dev/vda) tidak dapat diandalkan. Opsi ini dapat mengatur hal tersebut. Jika diset ketruemaka akan menggunakan nama block device yang ditentukan oleh Cinder. Nilai default adalahfalseyang berarti path dari device akan ditentukan oleh nomor serialnya serta pemetaan dari/dev/disk/by-id, dan ini merupakan cara yang direkomendasikan.ignore-volume-az(Opsional): Digunakan untuk mengatur penggunaan availability zone saat menautkan volumes Cinder. Jika Nova dan Cinder memiliki availability zones yang berbeda, opsi ini harus disettrue. Skenario seperti ini yang umumnya terjadi, yaitu saat terdapat banyak Nova availability zones namun hanya ada satu Cinder availability zone. Nilai default yaitufalsedigunakan untuk mendukung penggunaan pada rilis terdahulu, tetapi nilai ini dapat berubah pada rilis mendatang.
Jika menjalankan Kubernetes dengan versi <= 1.8 pada OpenStack yang menggunakan paths alih-alih
menggunakan port untuk membedakan antara endpoints, maka mungkin dibutuhkan untuk
secara eksplisit mengatur parameter bs-version. Contoh endpoint yang berdasarkan path yaitu
http://foo.bar/volume sedangkan endpoint yang berdasarkan port memiliki bentuk seperti ini
http://foo.bar:xxx.
Pada lingkungan yang menggunakan endpoint berdasarkan path dan Kubernetes menggunakan logika deteksi-otomatis yang lama, maka error BS API version autodetection failed. akan muncul saat mencoba
melepaskan volume. Untuk mengatasi isu ini, dimungkinkan
untuk memaksa penggunaan Cinder API versi 2 dengan menambahkan baris berikut ini pada konfigurasi penyedia cloud:
[BlockStorage]
bs-version=v2
Metadata
Konfigurasi untuk OpenStack berikut ini digunakan untuk mengatur metadata dan
harus berada pada bagian [Metadata] dari file cloud.conf:
-
search-order(Opsional): Konfigurasi berikut ini digunakan untuk mengatur bagaimana cara provider mengambil metadata terkait dengan instance yang dijalankannya. Nilai default yaituconfigDrive,metadataServiceyang berarti provider akan mengambil metadata terkait instance dari config drive terlebih dahulu jika tersedia, namun jika tidak maka akan menggunakan layanan metadata. Nilai alternatif lainnya yaitu:configDrive- Hanya mengambil metadata instance dari config drive.metadataService- Hanya mengambil data instance dari layanan metadata.metadataService,configDrive- Mengambil metadata instance dari layanan metadata terlebih dahulu jika tersedia, jika tidak maka akan mengambil dari config drive.
Pengaturan ini memang sebaiknya dilakukan sebab metadata pada config drive bisa saja lambat laun akan kedaluwarsa, sedangkan layanan metadata akan selalu menyediakan metadata yang paling mutakhir. Tidak semua penyedia layanan cloud OpenStack menyediakan kedua layanan config drive dan layanan metadata dan mungkin hanya salah satu saja yang tersedia. Oleh sebab itu nilai default diatur agar dapat memeriksa keduanya.
Router
Konfigurasi untuk Openstack berikut ini digunakan untuk mengatur plugin jaringan Kubernetes kubenet
dan harus berada pada bagian [Router] dari file cloud.conf:
router-id(Opsional): Jika Neutron pada underlying cloud mendukung ekstensiextraroutesmaka gunakanrouter-iduntuk menentukan router mana yang akan ditambahkan rute di dalamnya. Router yang dipilih harus menjangkau jaringan privat tempat node klaster berada (biasanya hanya ada satu jaringan node, dan nilai ini harus nilai dari default router pada jaringan node). Nilai ini dibutuhkan untuk dapat menggunakan kubenet pada OpenStack.
OVirt
Nama Node
Penyedia layanan cloud OVirt menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan VM FQDN (yang ditampilkan oleh OVirt di bawah <vm><guest_info><fqdn>...</fqdn></guest_info></vm>)
Photon
Nama Node
Penyedia layanan cloud Photon menggunakan hostname dari node (yang ditentukan kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node name harus sesuai dengan nama Photon VM (atau jika overrideIP diset ke true pada --cloud-config, nama Kubernetes Node harus sesuai dengan alamat IP Photon VM).
VSphere
Nama Node
Penyedia layanan cloud VSphere menggunakan hostname yang terdeteksi dari node (yang ditentukan oleh kubelet) sebagai nama dari objek Kubernetes Node.
Parameter --hostname-override diabaikan oleh penyedia layanan cloud VSphere.
IBM Cloud Kubernetes Service
Node Komputasi
Saat menggunakan layanan IBM Cloud Kubernetes Service, kamu dapat membuat klaster yang terdiri dari campuran antara mesin virtual dan fisik (bare metal) sebagai node di single zone atau multiple zones pada satu region. Untuk informasi lebih lanjut, lihat Perencanaan klaster dan pengaturan worker node.
Nama dari objek Kubernetes Node yaitu alamat IP privat dari IBM Cloud Kubernetes Service worker node instance.
Jaringan
Penyedia layanan IBM Cloud Kubernetes Service menyediakan VLAN untuk membuat jaringan node yang terisolasi dengan kinerja tinggi. Kamu juga dapat membuat custom firewall dan policy jaringan Calico untuk menambah lapisan perlindungan ekstra bagi klaster kamu, atau hubungkan klaster kamu dengan on-prem data center via VPN. Untuk informasi lebih lanjut, lihat Perencanaan jaringan privat dan in-cluster.
Untuk membuka aplikasi ke publik atau di dalam klaster, kamu dapat menggunakan NodePort, LoadBalancer, atau Ingress. Kamu juga dapat menyesuaikan aplikasi load balancer Ingress dengan anotasi. Untuk informasi lebih lanjut, lihat Perencanaan untuk membuka aplikasi dengan jaringan eksternal.
Penyimpanan
Penyedia layanan IBM Cloud Kubernetes Service memanfaatkan Kubernetes-native persistent volumes agar pengguna dapat melakukan mount file, block, dan penyimpanan objek cloud ke aplikasi mereka. Kamu juga dapat menggunakan database-as-a-service dan add-ons pihak ketiga sebagai penyimpanan persistent untuk data kamu. Untuk informasi lebih lanjut, lihat Perencanaan penyimpanan persistent yang selalu tersedia (highly available).
Baidu Cloud Container Engine
Nama Node
Penyedia layanan cloud Baidu menggunakan alamat IP privat dari node (yang ditentukan oleh kubelet atau menggunakan --hostname-override) sebagai nama dari objek Kubernetes Node.
Perlu diperhatikan bahwa nama Kubernetes Node harus sesuai dengan alamat IP privat dari Baidu VM.
4 - Mengelola Resource
Kamu telah melakukan deploy pada aplikasimu dan mengeksposnya melalui sebuah service. Lalu? Kubernetes menyediakan berbagai peralatan untuk membantu mengatur mekanisme deploy aplikasi, termasuk pengaturan kapasitas dan pembaruan. Diantara fitur yang akan didiskusikan lebih mendalam yaitu berkas konfigurasi dan label.
Mengelola konfigurasi resource
Banyak aplikasi memerlukan beberapa resource, seperti Deployment dan Service. Pengelolaan beberapa resource dapat disederhanakan dengan mengelompokkannya dalam berkas yang sama (dengan pemisah --- pada YAML). Contohnya:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Beberapa resource dapat dibuat seolah-olah satu resource:
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
Resource akan dibuat dalam urutan seperti pada berkas. Oleh karena itu, lebih baik menyalakan service lebih dahulu agar menjamin scheduler dapat menyebar pod yang terkait service selagi pod dibangkitkan oleh controller, seperti Deployment.
kubectl apply juga dapat menerima beberapa argumen -f:
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
Selain berkas, kita dapat juga memasukkan direktori sebagai argumen:
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectl akan membaca berkas apapun yang berakhiran .yaml, .yml, or .json.
Sangat disarankan untuk meletakkan sumber daya yang ada dalam microservice atau tier aplikasi yang sama dalam satu berkas, dan mengelompokkan semua berkas terkait aplikasimu dalam satu direktori. Jika tier masing-masing aplikasi terikat dengan DNS, maka kamu dapat melakukan deploy semua komponen teknologi yang dibutuhkan bersama-sama.
Lokasi konfigurasi dapat juga diberikan dalam bentuk URL. Ini berguna ketika ingin menjalankan berkas konfigurasi dari Github:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
Operasi majemuk dalam kubectl
Pembuatan resource bukanlah satu-satunya operasi yang bisa dijalankan kubectl secara majemuk. Contoh lainnya adalah mengekstrak nama resource dari berkas konfigurasi untuk menjalankan operasi lainnya, seperti untuk menghapus resource yang telah dibuat:
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Pada kasus dua resource, mudah untuk memasukkan keduanya pada command line menggunakan sintaks resource/nama:
kubectl delete deployments/my-nginx services/my-nginx-svc
Namun, untuk resource yang lebih banyak, memasukkan selektor (label query) menggunakan -l atau --selector untuk memfilter resource berdasarkan label akan lebih mudah:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
Karena kubectl mengembalikan nama resource yang sama dengan sintaks yang diterima, mudah untuk melanjutkan operasi menggunakan $() atau xargs:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
Dengan perintah di atas, pertama kita buat resource di dalam examples/application/nginx/. Lalu tampilkan resources yang terbentuk dengan format keluaran -o name (menampilkan tiap resource dalam format resource/nama). Kemudian lakukan grep hanya pada "service", dan tampilkan dengan kubectl get.
Untuk dapat menggunakan perintah di atas pada direktori yang bertingkat, kamu dapat memberi argumen --recursive atau -R bersama dengan argumen --filename,-f.
Misalnya ada sebuah direktori project/k8s/development memuat semua manifests yang berkaitan dengan development environment. Manifest akan tersusun berdasarkan tipe resource:
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
Secara default, menjalankan operasi majemuk pada project/k8s/development hanya akan terbatas pada direktori terluar saja. Sehingga ketika kita menjalankan operasi pembuatan dengan perintah berikut, kita akan mendapatkan pesan kesalahan:
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
Solusinya, tambahkan argumen --recursive atau -R bersama dengan --filename,-f, seperti:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Argumen --recursive berjalan pada operasi apapun yang menerima argumen --filename,-f seperti: kubectl {create,get,delete,describe,rollout} etc.
Argumen --recursive juga berjalan saat beberapa argumen -f diberikan:
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
Jika kamu tertarik mempelajari lebih lanjut tentang kubectl, silahkan baca Ikhtisar kubectl.
Memakai label secara efektif
Contoh yang kita lihat sejauh ini hanya menggunakan paling banyak satu label pada resource. Ada banyak skenario ketika membutuhkan beberapa label untuk membedakan sebuah kelompok dari yang lainnya.
Sebagai contoh, aplikasi yang berbeda akan menggunakan label app yang berbeda, tapi pada aplikasi multitier, seperti pada contoh buku tamu, tiap tier perlu dibedakan. Misal untuk menandai tier frontend bisa menggunakan label:
labels:
app: guestbook
tier: frontend
sementara itu Redis master dan slave memiliki label tier yang berbeda. Bisa juga menggunakan label tambahan role:
labels:
app: guestbook
tier: backend
role: master
dan
labels:
app: guestbook
tier: backend
role: slave
Label memungkinkan kita untuk memilah resource dengan pembeda berupa label:
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Deploy dengan Canary
Skenario lain yang menggunakan beberapa label yaitu saat membedakan deployment komponen yang sama namun dengan rilis atau konfigurasi yang berbeda. Adalah praktik yang umum untuk mendeploy sebuah canary dari rilis aplikasi yang baru (berdasarkan tag image dalam templat pod) bersamaan dengan rilis sebelumnya. Ini memungkinkan rilis yang baru dapat menerima live traffic sebelum benar-benar menggantikan rilis yang lama.
Salah satu alternatif yaitu kamu dapat memakai label track untuk membedakan antar rilis.
Rilis primer dan stabil akan memiliki label track yang berisi stable:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
kemudian kamu buat lagi rilis frontend buku tamu yang membawa label track yang berbeda (misal canary), sehingga pod dalam kedua rilis tidak beririsan:
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
Servis frontend akan meliputi kedua set replika dengan menentukan subset bersama dari para labelnya (tanpa track). Sehingga traffic akan diarahkan ke kedua aplikasi:
selector:
app: guestbook
tier: frontend
Kamu dapat mengatur jumlah replika rilis stable dan canary untuk menentukan rasio dari tiap rilis yang akan menerima traffic production live (dalam kasus ini 3:1). Ketika telah yakin, kamu dapat memindahkan track stable ke rilis baru dan menghapus canary.
Untuk contoh yang lebih jelas, silahkan cek tutorial melakukan deploy Ghost.
Memperbarui label
Kadang, pod dan resource lain yang sudah ada harus dilabeli ulang sebelum membuat resource baru. Hal ini dapat dilakukan dengan perintah kubectl label.
Contohnya jika kamu ingin melabeli ulang semua pod nginx sebagai frontend tier, tinggal jalankan:
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
Perintah ini melakukan filter pada semua pod dengan label "app=nginx", lalu melabelinya dengan "tier=fe". Untuk melihat pod yang telah dilabeli, jalankan:
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
Akan muncul semua pod dengan "app=nginx" dan sebuah kolom label tambahan yaitu tier (ditentukan dengan -L atau --label-columns).
Untuk informasi lebih lanjut, silahkan baca label dan kubectl label.
Memperbarui anotasi
Kadang resource perlu ditambahkan anotasi. Anotasi adalah metadata sembarang yang tidak unik, seperti tools, libraries, dsb yang digunakan oleh klien API . Ini dapat dilakukan dengan kubectl annotate. Sebagai contoh:
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
Untuk informasi lebih lanjut, silahkan lihat laman annotations dan kubectl annotate.
Memperbesar dan memperkecil aplikasi kamu
Saat beban aplikasi naik maupun turun, mudah untuk mengubah kapasitas dengan kubectl. Contohnya, untuk menurunkan jumlah replika nginx dari 3 ke 1, lakukan:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
Sekarang kamu hanya memiliki satu pod yang dikelola oleh deployment.
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
Agar sistem dapat menyesuaikan jumlah replika nginx yang dibutuhkan secara otomatis dari 1 hingga 3, lakukan:
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
Sekarang jumlah replika nginx akan secara otomatis naik dan turun sesuai kebutuhan.
Informasi tambahan dapat dilihat pada dokumen kubectl scale, kubectl autoscale dan horizontal pod autoscaler.
Pembaruan resource di tempat
Kadang kita perlu membuat pembaruan kecil, yang tidak mengganggu pada resource yang telah dibuat.
kubectl apply
Disarankan untuk menyimpan berkas-berkas konfigurasi dalam source control (lihat konfigurasi sebagai kode). Sehingga berkas dapat dipelihara dan diatur dalam versi bersama dengan kode milik resource yang diatur oleh konfigurasi tersebut. Berikutnya, kamu dapat menggunakan kubectl apply untuk membarui perubahan konfigurasi ke klaster.
Perintah ini akan membandingkan versi konfigurasi yang disuplai dengan versi sebelumnya yang telah berjalan dan memasang perubahan yang kamu buat tanpa mengganti properti yang tidak berubah sama sekali.
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
Perhatikan bahwa kubectl apply memasang anotasi pada resource untuk menentukan perubahan pada konfigurasi sejak terakhir dipanggil. Ketika dijalankan, kubectl apply melakukan pembandingan three-way antara konfigurasi sebelumnya, masukan yang disuplai, dan konfigurasi resource sekarang, untuk dapat menentukan cara memodifikasi resource.
Saat ini, resource dibuat tanpa ada anotasi. Jadi pemanggilan pertama pada kubectl apply akan dikembalikan pada perbandingan two-way antara masukan pengguna dan konfigurasi resource sekarang. Saat pemanggilan pertama ini, tidak ada penghapusan set properti yang terdeteksi saat resource dibuat. Sehingga, tidak ada yang dihapus.
Tiap kubectl apply, atau perintah lain yang memodifikasi konfigurasi seperti kubectl replace dan kubectl edit dijalankan, anotasi akan diperbarui. Sehingga memungkinkan operasi kubectl apply untuk mendeteksi dan melakukan penghapusan secara perbandingan three-way.
kubectl edit
Sebagai alternatif, kamu juga dapat membarui resource dengan kubectl edit:
kubectl edit deployment/my-nginx
Ini sama dengan melakukan get pada resource, mengubahnya di text editor, kemudian menjalankanapply pada resource dengan versi terkini:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# lakukan pengubahan, lalu simpan berkas
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
Cara demikian memungkinkan kamu membuat perubahan signifikan dengan mudah. Lihat bahwa kamu juga dapat menentukan editor dengan variabel environment EDITOR atau KUBE_EDITOR.
Untuk informasi tambahan, silahkan lihat laman kubectl edit.
kubectl patch
Kamu dapat menggunakan kubectl patch untuk membarui obyek API di tempat. Perintah ini mendukung patch JSON, patch gabungan JSON, dan strategic merge patch. Lihat
Update API Objects in Place Using kubectl patch
dan
kubectl patch.
Pembaruan disruptif
Pada kasus tertentu, kamu mungkin perlu memperbarui field resource yang tidak dapat diperbarui setelah diinisiasi atau kamu ingin membuat perubahan rekursif segera, seperti memperbaiki pod yang rusak saat menjalankan Deployment. Untuk mengubah field seperti itu, gunakan replace --force yang akan menghapus dan membuat ulang resource. Dalam kasus ini kamu dapat mengubah berkas konfigurasi awalnya:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
Membarui aplikasi tanpa memadamkan servis
Suatu saat, kamu akan perlu untuk membarui aplikasi yang telah terdeploy, biasanya dengan mengganti image atau tag sebagaimana dalam skenario canary deployment di atas. kubectl mendukung beberapa operasi pembaruan, masing-masing dapat digunakan pada skenario berbeda.
Kami akan memandumu untuk membuat dan membarui aplikasi melalui Deployment.
Misal kamu telah menjalankan nginx versi 1.7.9:
kubectl run my-nginx --image=nginx:1.7.9 --replicas=3
deployment.apps/my-nginx created
Untuk memperbarui versi ke 1.9.1, ganti .spec.template.spec.containers[0].image dari nginx:1.7.9 ke nginx:1.9.1, dengan perintah kubectl yang telah dipelajari di atas.
kubectl edit deployment/my-nginx
Selesai! Deployment akan memperbarui aplikasi nginx yang terdeploy secara berangsur di belakang. Dia akan menjamin hanya ada sekian replika lama yang akan down selagi pembaruan berjalan dan hanya ada sekian replika baru akan dibuat melebihi jumlah pod. Untuk mempelajari lebih lanjut, kunjungi laman Deployment.
Selanjutnya
5 - Jaringan Kluster
Jaringan adalah bagian utama dari Kubernetes, tetapi bisa menjadi sulit untuk memahami persis bagaimana mengharapkannya bisa bekerja. Ada 4 masalah yang berbeda untuk diatasi:
- Komunikasi antar kontainer yang sangat erat: hal ini diselesaikan oleh
Pod dan komunikasi
localhost. - Komunikasi antar Pod: ini adalah fokus utama dari dokumen ini.
- Komunikasi Pod dengan Service: ini terdapat di Service.
- Komunikasi eksternal dengan Service: ini terdapat di Service.
Kubernetes adalah tentang berbagi mesin antar aplikasi. Pada dasarnya, saat berbagi mesin harus memastikan bahwa dua aplikasi tidak mencoba menggunakan port yang sama. Mengkoordinasikan port di banyak pengembang sangat sulit dilakukan pada skala yang berbeda dan memaparkan pengguna ke masalah tingkat kluster yang di luar kendali mereka.
Alokasi port yang dinamis membawa banyak komplikasi ke sistem - setiap aplikasi harus menganggap port sebagai flag, server API harus tahu cara memasukkan nomor port dinamis ke dalam blok konfigurasi, Service-Service harus tahu cara menemukan satu sama lain, dll. Sebaliknya daripada berurusan dengan ini, Kubernetes mengambil pendekatan yang berbeda.
Model jaringan Kubernetes
Setiap Pod mendapatkan alamat IP sendiri. Ini berarti kamu tidak perlu secara langsung membuat tautan antara Pod dan kamu hampir tidak perlu berurusan dengan memetakan port kontainer ke port pada host. Ini menciptakan model yang bersih, kompatibel dengan yang sebelumnya dimana Pod dapat diperlakukan seperti halnya VM atau host fisik dari perspektif alokasi port, penamaan, service discovery, load balancing, konfigurasi aplikasi, dan migrasi.
Kubernetes memberlakukan persyaratan mendasar berikut pada setiap implementasi jaringan (kecuali kebijakan segmentasi jaringan yang disengaja):
- Pod pada suatu Node dapat berkomunikasi dengan semua Pod pada semua Node tanpa NAT
- agen pada suatu simpul (mis. daemon sistem, kubelet) dapat berkomunikasi dengan semua Pod pada Node itu
Catatan: Untuk platform yang mendukung Pod yang berjalan di jaringan host (mis. Linux):
- Pod di jaringan host dari sebuah Node dapat berkomunikasi dengan semua Pod pada semua Node tanpa NAT
Model ini tidak hanya sedikit kompleks secara keseluruhan, tetapi pada prinsipnya kompatibel dengan keinginan Kubernetes untuk memungkinkan low-friction porting dari aplikasi dari VM ke kontainer. Jika pekerjaan kamu sebelumnya dijalankan dalam VM, VM kamu memiliki IP dan dapat berbicara dengan VM lain di proyek yang sama. Ini adalah model dasar yang sama.
Alamat IP Kubernetes ada di lingkup Pod - kontainer dalam Pod berbagi jaringan namespace mereka - termasuk alamat IP mereka. Ini berarti bahwa kontainer dalam Pod semua dapat mencapai port satu sama lain di _localhost_. Ini juga berarti bahwa kontainer dalam Pod harus mengoordinasikan penggunaan port, tetapi ini tidak berbeda dari proses di VM. Ini disebut model "IP-per-pod".
Bagaimana menerapkan model jaringan Kubernetes
Ada beberapa cara agar model jaringan ini dapat diimplementasikan. Dokumen ini bukan studi lengkap tentang berbagai metode, tetapi semoga berfungsi sebagai pengantar ke berbagai teknologi dan berfungsi sebagai titik awal.
Opsi jaringan berikut ini disortir berdasarkan abjad - urutan tidak menyiratkan status istimewa apa pun.
ACI
Infrastruktur Sentral Aplikasi Cisco menawarkan solusi SDN overlay dan underlay terintegrasi yang mendukung kontainer, mesin virtual, dan bare metal server. ACI menyediakan integrasi jaringan kontainer untuk ACI. Tinjauan umum integrasi disediakan di sini.
AOS dari Apstra
AOS adalah sistem Jaringan Berbasis Intent yang menciptakan dan mengelola lingkungan pusat data yang kompleks dari platform terintegrasi yang sederhana. AOS memanfaatkan desain terdistribusi sangat scalable untuk menghilangkan pemadaman jaringan sambil meminimalkan biaya.
Desain Referensi AOS saat ini mendukung host yang terhubung dengan Lapis-3 yang menghilangkan masalah peralihan Lapis-2 yang lama. Host Lapis-3 ini bisa berupa server Linux (Debian, Ubuntu, CentOS) yang membuat hubungan tetangga BGP secara langsung dengan top of rack switches (TORs). AOS mengotomatisasi kedekatan perutean dan kemudian memberikan kontrol yang halus atas route health injections (RHI) yang umum dalam deployment Kubernetes.
AOS memiliki banyak kumpulan endpoint REST API yang memungkinkan Kubernetes dengan cepat mengubah kebijakan jaringan berdasarkan persyaratan aplikasi. Peningkatan lebih lanjut akan mengintegrasikan model Grafik AOS yang digunakan untuk desain jaringan dengan penyediaan beban kerja, memungkinkan sistem manajemen ujung ke ujung untuk layanan cloud pribadi dan publik.
AOS mendukung penggunaan peralatan vendor umum dari produsen termasuk Cisco, Arista, Dell, Mellanox, HPE, dan sejumlah besar sistem white-box dan sistem operasi jaringan terbuka seperti Microsoft SONiC, Dell OPX, dan Cumulus Linux.
Detail tentang cara kerja sistem AOS dapat diakses di sini: http://www.apstra.com/products/how-it-works/
AWS VPC CNI untuk Kubernetes
AWS VPC CNI menawarkan jaringan AWS Virtual Private Cloud (VPC) terintegrasi untuk kluster Kubernetes. Plugin CNI ini menawarkan throughput dan ketersediaan tinggi, latensi rendah, dan jitter jaringan minimal. Selain itu, pengguna dapat menerapkan jaringan AWS VPC dan praktik keamanan terbaik untuk membangun kluster Kubernetes. Ini termasuk kemampuan untuk menggunakan catatan aliran VPC, kebijakan perutean VPC, dan grup keamanan untuk isolasi lalu lintas jaringan.
Menggunakan plugin CNI ini memungkinkan Pod Kubernetes memiliki alamat IP yang sama di dalam Pod seperti yang mereka lakukan di jaringan VPC. CNI mengalokasikan AWS Elastic Networking Interfaces (ENIs) ke setiap node Kubernetes dan menggunakan rentang IP sekunder dari setiap ENI untuk Pod pada Node. CNI mencakup kontrol untuk pra-alokasi ENI dan alamat IP untuk waktu mulai Pod yang cepat dan memungkinkan kluster besar hingga 2.000 Node.
Selain itu, CNI dapat dijalankan bersama Calico untuk penegakan kebijakan jaringan. Proyek AWS VPC CNI adalah open source dengan dokumentasi di GitHub.
Big Cloud Fabric dari Big Switch Networks
Big Cloud Fabric adalah arsitektur jaringan asli layanan cloud, yang dirancang untuk menjalankan Kubernetes di lingkungan cloud pribadi / lokal. Dengan menggunakan SDN fisik & virtual terpadu, Big Cloud Fabric menangani masalah yang sering melekat pada jaringan kontainer seperti penyeimbangan muatan, visibilitas, pemecahan masalah, kebijakan keamanan & pemantauan lalu lintas kontainer.
Dengan bantuan arsitektur multi-penyewa Pod virtual pada Big Cloud Fabric, sistem orkestrasi kontainer seperti Kubernetes, RedHat OpenShift, Mesosphere DC/OS & Docker Swarm akan terintegrasi secara alami bersama dengan sistem orkestrasi VM seperti VMware, OpenStack & Nutanix. Pelanggan akan dapat terhubung dengan aman berapa pun jumlah klusternya dan memungkinkan komunikasi antar penyewa di antara mereka jika diperlukan.
Terbaru ini BCF diakui oleh Gartner sebagai visioner dalam Magic Quadrant. Salah satu penyebaran BCF Kubernetes di tempat (yang mencakup Kubernetes, DC/OS & VMware yang berjalan di beberapa DC di berbagai wilayah geografis) juga dirujuk di sini.
Cilium
Cilium adalah perangkat lunak open source untuk menyediakan dan secara transparan mengamankan konektivitas jaringan antar kontainer aplikasi. Cilium mengetahui L7/HTTP dan dapat memberlakukan kebijakan jaringan pada L3-L7 menggunakan model keamanan berbasis identitas yang dipisahkan dari pengalamatan jaringan.
CNI-Genie dari Huawei
CNI-Genie adalah plugin CNI yang memungkinkan Kubernetes [secara bersamaan memiliki akses ke berbagai implementasi](https://github.com/Huawei-PaaS /CNI-Genie/blob/master/docs/multiple-cni-plugins/README.md#what-cni-genie-feature-1-multiple-cni-plugins-enables) dari [model jaringan Kubernetes] (https://git.k8s.io/website/docs/concepts/cluster-administration/networking.md#kubernetes-model) dalam runtime. Ini termasuk setiap implementasi yang berjalan sebagai plugin CNI, seperti Flannel, Calico, Romana, Weave-net.
CNI-Genie juga mendukung menetapkan beberapa alamat IP ke sebuah Pod, masing-masing dari plugin CNI yang berbeda.
cni-ipvlan-vpc-k8s
cni-ipvlan-vpc-k8s berisi satu set plugin CNI dan IPAM untuk menyediakan kemudahan, host-lokal, latensi rendah, throughput tinggi , dan tumpukan jaringan yang sesuai untuk Kubernetes dalam lingkungan Amazon Virtual Private Cloud (VPC) dengan memanfaatkan Amazon Elastic Network Interfaces (ENI) dan mengikat IP yang dikelola AWS ke Pod-Pod menggunakan driver IPvlan kernel Linux dalam mode L2.
Plugin ini dirancang untuk secara langsung mengkonfigurasi dan deploy dalam VPC. Kubelet melakukan booting dan kemudian mengkonfigurasi sendiri dan memperbanyak penggunaan IP mereka sesuai kebutuhan tanpa memerlukan kompleksitas yang sering direkomendasikan untuk mengelola jaringan overlay, BGP, menonaktifkan pemeriksaan sumber/tujuan, atau menyesuaikan tabel rute VPC untuk memberikan subnet per instance ke setiap host (yang terbatas hingga 50-100 masukan per VPC). Singkatnya, cni-ipvlan-vpc-k8s secara signifikan mengurangi kompleksitas jaringan yang diperlukan untuk menggunakan Kubernetes yang berskala di dalam AWS.
Contiv
Contiv menyediakan jaringan yang dapat dikonfigurasi (native l3 menggunakan BGP, overlay menggunakan vxlan, classic l2, atau Cisco-SDN / ACI) untuk berbagai kasus penggunaan. Contiv semuanya open sourced.
Contrail / Tungsten Fabric
Contrail, berdasarkan Tungsten Fabric, adalah platform virtualisasi jaringan dan manajemen kebijakan multi-cloud yang benar-benar terbuka. Contrail dan Tungsten Fabric terintegrasi dengan berbagai sistem orkestrasi seperti Kubernetes, OpenShift, OpenStack dan Mesos, dan menyediakan mode isolasi yang berbeda untuk mesin virtual, banyak kontainer / banyak Pod dan beban kerja bare metal.
DANM
[DANM] (https://github.com/nokia/danm) adalah solusi jaringan untuk beban kerja telco yang berjalan di kluster Kubernetes. Dibangun dari komponen-komponen berikut:
- Plugin CNI yang mampu menyediakan antarmuka IPVLAN dengan fitur-fitur canggih
- Modul IPAM built-in dengan kemampuan mengelola dengan jumlah banyak, cluster-wide, discontinous jaringan L3 dan menyediakan skema dinamis, statis, atau tidak ada permintaan skema IP
- Metaplugin CNI yang mampu melampirkan beberapa antarmuka jaringan ke kontainer, baik melalui CNI sendiri, atau mendelegasikan pekerjaan ke salah satu solusi CNI populer seperti SRI-OV, atau Flannel secara paralel
- Pengontrol Kubernetes yang mampu mengatur secara terpusat antarmuka VxLAN dan VLAN dari semua host Kubernetes
- Pengontrol Kubernetes lain yang memperluas konsep service discovery berbasis servis untuk bekerja di semua antarmuka jaringan Pod
Dengan toolset ini, DANM dapat memberikan beberapa antarmuka jaringan yang terpisah, kemungkinan untuk menggunakan ujung belakang jaringan yang berbeda dan fitur IPAM canggih untuk Pod.
Flannel
[Flannel] (https://github.com/coreos/flannel#flannel) adalah jaringan overlay yang sangat sederhana yang memenuhi persyaratan Kubernetes. Banyak orang telah melaporkan kesuksesan dengan Flannel dan Kubernetes.
Google Compute Engine (GCE)
Untuk skrip konfigurasi kluster Google Compute Engine, perutean lanjutan digunakan untuk menetapkan setiap VM subnet (standarnya adalah /24 - 254 IP). Setiap lalu lintas yang terikat untuk subnet itu akan dialihkan langsung ke VM oleh fabric jaringan GCE. Ini adalah tambahan untuk alamat IP "utama" yang ditugaskan untuk VM, yang NAT'ed untuk akses internet keluar. Sebuah linux bridge (disebut cbr0) dikonfigurasikan untuk ada pada subnet itu, dan diteruskan ke flag -bridge milik docker.
Docker dimulai dengan:
DOCKER_OPTS="--bridge=cbr0 --iptables=false --ip-masq=false"
Jembatan ini dibuat oleh Kubelet (dikontrol oleh flag --network-plugin=kubenet) sesuai dengan .spec.podCIDR yang dimiliki oleh Node.
Docker sekarang akan mengalokasikan IP dari blok cbr-cidr. Kontainer dapat menjangkau satu sama lain dan Node di atas jembatan cbr0. IP-IP tersebut semuanya dapat dirutekan dalam jaringan proyek GCE.
GCE sendiri tidak tahu apa-apa tentang IP ini, jadi tidak akan NAT untuk lalu lintas internet keluar. Untuk mencapai itu aturan iptables digunakan untuk menyamar (alias SNAT - untuk membuatnya seolah-olah paket berasal dari lalu lintas Node itu sendiri) yang terikat untuk IP di luar jaringan proyek GCE (10.0.0.0/8).
iptables -t nat -A POSTROUTING ! -d 10.0.0.0/8 -o eth0 -j MASQUERADE
Terakhir IP forwarding diaktifkan di kernel (sehingga kernel akan memproses paket untuk kontainer yang dijembatani):
sysctl net.ipv4.ip_forward=1
Hasil dari semua ini adalah bahwa semua Pod dapat saling menjangkau dan dapat keluar lalu lintas ke internet.
Jaguar
Jaguar adalah solusi open source untuk jaringan Kubernetes berdasarkan OpenDaylight. Jaguar menyediakan jaringan overlay menggunakan vxlan dan Jaguar CNIPlugin menyediakan satu alamat IP per Pod.
Knitter
Knitter adalah solusi jaringan yang mendukung banyak jaringan di Kubernetes. Solusi ini menyediakan kemampuan manajemen penyewa dan manajemen jaringan. Knitter mencakup satu set solusi jaringan kontainer NFV ujung ke ujung selain beberapa pesawat jaringan, seperti menjaga alamat IP untuk aplikasi, migrasi alamat IP, dll.
Kube-OVN
Kube-OVN adalah fabric jaringan kubernetes berbasis OVN untuk enterprises. Dengan bantuan OVN/OVS, solusi ini menyediakan beberapa fitur jaringan overlay canggih seperti subnet, QoS, alokasi IP statis, mirroring traffic, gateway, kebijakan jaringan berbasis openflow, dan proksi layanan.
Kube-router
Kube-router adalah solusi jaringan yang dibuat khusus untuk Kubernetes yang bertujuan untuk memberikan kinerja tinggi dan kesederhanaan operasional. Kube-router menyediakan Linux LVS/IPVS berbasis proksi layanan, solusi jaringan berbasis penerusan pod-to-pod Linux kernel tanpa overlay, dan penegak kebijakan jaringan berbasis iptables/ipset.
L2 networks and linux bridging
Jika Anda memiliki jaringan L2 yang "bodoh", seperti saklar sederhana di environment "bare-metal", kamu harus dapat melakukan sesuatu yang mirip dengan pengaturan GCE di atas. Perhatikan bahwa petunjuk ini hanya dicoba dengan sangat sederhana - sepertinya berhasil, tetapi belum diuji secara menyeluruh. Jika kamu menggunakan teknik ini dan telah menyempurnakan prosesnya, tolong beri tahu kami.
Ikuti bagian "With Linux Bridge devices" dari tutorial yang sangat bagus ini dari Lars Kellogg-Stedman.
Multus (plugin Multi-Jaringan)
Multus adalah plugin Multi CNI untuk mendukung fitur Banyak Jaringan di Kubernetes menggunakan objek jaringan berbasis CRD di Kubernetes.
Multus mendukung semua plugin referensi (mis. Flannel, DHCP, [Macvlan](https://github.com/containernetworking/plugins/tree/master/plugins/main / macvlan)) yang mengimplementasikan spesifikasi CNI dan plugin pihak ke-3 (mis. Calico, Weave, Cilium, Contiv). Selain itu, Multus mendukung SRIOV, DPDK, OVS- DPDK & VPP beban kerja di Kubernetes dengan aplikasi cloud asli dan aplikasi berbasis NFV di Kubernetes.
NSX-T
VMware NSX-T adalah virtualisasi jaringan dan platform keamanan. NSX-T dapat menyediakan virtualisasi jaringan untuk lingkungan multi-cloud dan multi-hypervisor dan berfokus pada kerangka kerja dan arsitektur aplikasi yang muncul yang memiliki titik akhir dan tumpukan teknologi yang heterogen. Selain hypervisor vSphere, lingkungan ini termasuk hypervisor lainnya seperti KVM, wadah, dan bare metal.
NSX-T Container Plug-in (NCP) menyediakan integrasi antara NSX-T dan pembuat wadah seperti Kubernetes, serta integrasi antara NSX-T dan platform CaaS / PaaS berbasis-kontainer seperti Pivotal Container Service (PKS) dan OpenShift.
Nuage Networks VCS (Layanan Cloud Virtual)
Nuage menyediakan platform SDN (Software-Defined Networking) berbasis kebijakan yang sangat skalabel. Nuage menggunakan Open vSwitch open source untuk data plane bersama dengan SDN Controller yang kaya fitur yang dibangun pada standar terbuka.
Platform Nuage menggunakan overlay untuk menyediakan jaringan berbasis kebijakan yang mulus antara Kubernetes Pod-Pod dan lingkungan non-Kubernetes (VM dan server bare metal). Model abstraksi kebijakan Nuage dirancang dengan mempertimbangkan aplikasi dan membuatnya mudah untuk mendeklarasikan kebijakan berbutir halus untuk aplikasi. Mesin analisis real-time platform memungkinkan pemantauan visibilitas dan keamanan untuk aplikasi Kubernetes.
OVN (Open Virtual Networking)
OVN adalah solusi virtualisasi jaringan opensource yang dikembangkan oleh komunitas Open vSwitch. Ini memungkinkan seseorang membuat switch logis, router logis, ACL stateful, load-balancers dll untuk membangun berbagai topologi jaringan virtual. Proyek ini memiliki plugin dan dokumentasi Kubernetes spesifik di ovn-kubernetes.
Project Calico
Project Calico adalah penyedia jaringan wadah sumber terbuka dan mesin kebijakan jaringan.
Calico menyediakan solusi jaringan dan kebijakan kebijakan jaringan yang sangat berskala untuk menghubungkan Pod Kubernetes berdasarkan prinsip jaringan IP yang sama dengan internet, untuk Linux (open source) dan Windows (milik - tersedia dari Tigera). Calico dapat digunakan tanpa enkapsulasi atau overlay untuk menyediakan jaringan pusat data skala tinggi yang berkinerja tinggi. Calico juga menyediakan kebijakan keamanan jaringan berbutir halus, berdasarkan niat untuk Pod Kubernetes melalui firewall terdistribusi.
Calico juga dapat dijalankan dalam mode penegakan kebijakan bersama dengan solusi jaringan lain seperti Flannel, alias kanal, atau jaringan GCE, AWS atau Azure asli.
Romana
Romana adalah jaringan sumber terbuka dan solusi otomasi keamanan yang memungkinkan kamu menggunakan Kubernetes tanpa jaringan hamparan. Romana mendukung Kubernetes Kebijakan Jaringan untuk memberikan isolasi di seluruh ruang nama jaringan.
Weave Net dari Weaveworks
Weave Net adalah jaringan yang tangguh dan mudah digunakan untuk Kubernetes dan aplikasi yang dihostingnya. Weave Net berjalan sebagai plug-in CNI atau berdiri sendiri. Di kedua versi, itu tidak memerlukan konfigurasi atau kode tambahan untuk dijalankan, dan dalam kedua kasus, jaringan menyediakan satu alamat IP per Pod - seperti standar untuk Kubernetes.
Selanjutnya
Desain awal model jaringan dan alasannya, dan beberapa rencana masa depan dijelaskan secara lebih rinci dalam dokumen desain jaringan.
6 - Arsitektur Logging
Log aplikasi dan sistem dapat membantu kamu untuk memahami apa yang terjadi di dalam klaster kamu. Log berguna untuk mengidentifikasi dan menyelesaikan masalah serta memonitor aktivitas klaster. Hampir semua aplikasi modern mempunyai sejenis mekanisme log sehingga hampir semua mesin kontainer didesain untuk mendukung suatu mekanisme logging. Metode logging yang paling mudah untuk aplikasi dalam bentuk kontainer adalah menggunakan standard output dan standard error.
Namun, fungsionalitas bawaan dari mesin kontainer atau runtime biasanya tidak cukup memadai sebagai solusi log. Contohnya, jika sebuah kontainer gagal, sebuah pod dihapus, atau suatu node mati, kamu biasanya tetap menginginkan untuk mengakses log dari aplikasimu. Oleh sebab itu, log sebaiknya berada pada penyimpanan dan lifecyle yang terpisah dari node, pod, atau kontainer. Konsep ini dinamakan sebagai logging pada level klaster. Logging pada level klaster ini membutuhkan backend yang terpisah untuk menyimpan, menganalisis, dan mengkueri log. Kubernetes tidak menyediakan solusi bawaan untuk penyimpanan data log, namun kamu dapat mengintegrasikan beragam solusi logging yang telah ada ke dalam klaster Kubernetes kamu.
Arsitektur logging pada level klaster yang akan dijelaskan berikut mengasumsikan bahwa sebuah logging backend telah tersedia baik di dalam maupun di luar klastermu. Meskipun kamu tidak tertarik menggunakan logging pada level klaster, penjelasan tentang bagaimana log disimpan dan ditangani pada node di bawah ini mungkin dapat berguna untukmu.
Hal dasar logging pada Kubernetes
Pada bagian ini, kamu dapat melihat contoh tentang dasar logging pada Kubernetes yang mengeluarkan data pada standard output. Demonstrasi berikut ini menggunakan sebuah spesifikasi pod dengan kontainer yang akan menuliskan beberapa teks ke standard output tiap detik.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Untuk menjalankan pod ini, gunakan perintah berikut:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
Keluarannya adalah:
pod/counter created
Untuk mengambil log, gunakan perintah kubectl logs sebagai berikut:
kubectl logs counter
Keluarannya adalah:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Kamu dapat menambahkan parameter --previous pada perintah kubectl logs untuk mengambil log dari kontainer sebelumnya yang gagal atau crash. Jika pod kamu memiliki banyak kontainer, kamu harus menspesifikasikan kontainer mana yang kamu ingin akses lognya dengan menambahkan nama kontainer pada perintah tersebut. Lihat dokumentasi kubectl logs untuk informasi lebih lanjut.
Node-level logging
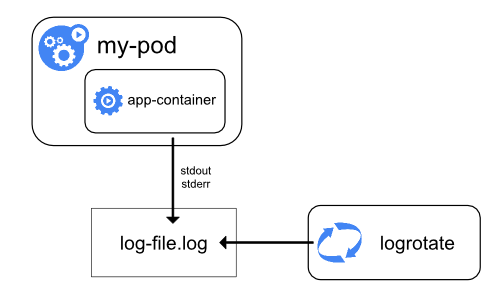
Semua hal yang ditulis oleh aplikasi dalam kontainer ke stdout dan stderr akan ditangani dan diarahkan ke suatu tempat oleh mesin atau engine kontainer. Contohnya,mesin kontainer Docker akan mengarahkan kedua aliran tersebut ke suatu logging driver, yang akan dikonfigurasi pada Kubernetes untuk menuliskan ke dalam berkas dalam format json.
Catatan:
Logging driver json dari Docker memperlakukan tiap baris sebagai pesan yang terpisah. Saat menggunakan logging driver Docker, tidak ada dukungan untuk menangani pesan multi-line. Kamu harus menangani pesan multi-line pada level agen log atau yang lebih tinggi.Secara default, jika suatu kontainer restart, kubelet akan menjaga kontainer yang mati tersebut beserta lognya. Namun jika suatu pod dibuang dari node, maka semua hal dari kontainernya juga akan dibuang, termasuk lognya.
Hal lain yang perlu diperhatikan dalam logging pada level node adalah implementasi rotasi log, sehingga log tidak menghabiskan semua penyimpanan yang tersedia pada node. Kubernetes saat ini tidak bertanggung jawab dalam melakukan rotasi log, namun deployment tool seharusnya memberikan solusi terhadap masalah tersebut.
Contohnya, pada klaster Kubernetes, yang di deployed menggunakan kube-up.sh, terdapat alat bernama logrotate yang dikonfigurasi untuk berjalan tiap jamnya. Kamu juga dapat menggunakan runtime kontainer untuk melakukan rotasi log otomatis, misalnya menggunakan log-opt Docker.
Pada kube-up.sh, metode terakhir digunakan untuk COS image pada GCP, sedangkan metode pertama digunakan untuk lingkungan lainnya. Pada kedua metode, secara default akan dilakukan rotasi pada saat berkas log melewati 10MB.
Sebagai contoh, kamu dapat melihat informasi lebih rinci tentang bagaimana kube-up.sh mengatur logging untuk COS image pada GCP yang terkait dengan script.
Saat kamu menjalankan perintah kubectl logs seperti pada contoh tadi, kubelet di node tersebut akan menangani permintaan untuk membaca langsung isi berkas log sebagai respon.
Catatan:
Saat ini, jika suatu sistem eksternal telah melakukan rotasi, hanya konten dari berkas log terbaru yang akan tersedia melalui perintahkubectl logs. Contoh, jika terdapat sebuah berkas 10MB, logrotate akan melakukan rotasi sehingga akan ada dua buah berkas, satu dengan ukuran 10MB, dan satu berkas lainnya yang kosong. Maka kubectl logs akan mengembalikan respon kosong.Komponen sistem log
Terdapat dua jenis komponen sistem: yaitu yang berjalan di dalam kontainer dan komponen lain yang tidak berjalan di dalam kontainer. Sebagai contoh:
- Kubernetes scheduler dan kube-proxy berjalan di dalam kontainer.
- Kubelet dan runtime kontainer, contohnya Docker, tidak berjalan di dalam kontainer.
Pada mesin yang menggunakan systemd, kubelet dan runtime runtime menulis ke journald. Jika systemd tidak tersedia, keduanya akan menulis ke berkas .log pada folder /var/log.
Komponen sistem di dalam kontainer akan selalu menuliskan ke folder /var/log, melewati mekanisme default logging. Mereka akan menggunakan logging library klog.
Kamu dapat menemukan konvensi tentang tingkat kegawatan logging untuk komponen-komponen tersebut pada dokumentasi development logging.
Seperti halnya pada log kontainer, komponen sistem yang menuliskan log pada folder /var/log juga harus melakukan rotasi log. Pada klaster Kubernetes yang menggunakan kube-up.sh, log tersebut telah dikonfigurasi dan akan dirotasi oleh logrotate secara harian atau saat ukuran log melebihi 100MB.
Arsitektur klaster-level logging
Meskipun Kubernetes tidak menyediakan solusi bawaan untuk logging level klaster, ada beberapa pendekatan yang dapat kamu pertimbangkan. Berikut beberapa diantaranya:
- Menggunakan agen logging pada level node yang berjalan pada setiap node.
- Menggunakan kontainer sidecar khusus untuk logging aplikasi di dalam pod.
- Mengeluarkan log langsung ke backend dari dalam aplikasi
Menggunakan agen node-level logging
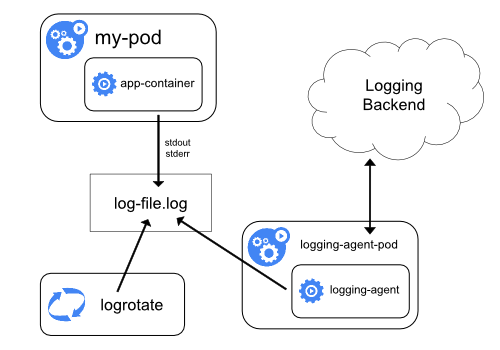
Kamu dapat mengimplementasikan klaster-level logging dengan menggunakan agen yang berjalan pada setiap node. Agen logging merupakan perangkat khusus yang akan mengekspos log atau mengeluarkan log ke backend. Umumnya agen logging merupakan kontainer yang memiliki akses langsung ke direktori tempat berkas log berada dari semua kontainer aplikasi yang berjalan pada node tersebut.
Karena agen logging harus berjalan pada setiap node, umumnya dilakukan dengan menggunakan replika DaemonSet, manifest pod, atau menjalankan proses khusus pada node. Namun dua cara terakhir sudah dideprekasi dan sangat tidak disarankan.
Menggunakan agen logging pada level node merupakan cara yang paling umum dan disarankan untuk klaster Kubernetes. Hal ini karena hanya dibutuhkan satu agen tiap node dan tidak membutuhkan perubahan apapun dari sisi aplikasi yang berjalan pada node. Namun, node-level logging hanya dapat dilakukan untuk aplikasi yang menggunakan standard output dan standard error.
Kubernetes tidak menspesifikasikan khusus suatu agen logging, namun ada dua agen logging yang dimasukkan dalam rilis Kubernetes: Stackdriver Logging untuk digunakan pada Google Cloud Platform, dan Elasticsearch. Kamu dapat melihat informasi dan instruksi pada masing-masing dokumentasi. Keduanya menggunakan fluentd dengan konfigurasi kustom sebagai agen pada node.
Menggunakan kontainer sidecar dengan agen logging
Kamu dapat menggunakan kontainer sidecar dengan salah satu cara berikut:
- Kontainer sidecar mengeluarkan log aplikasi ke
stdoutmiliknya sendiri. - Kontainer sidecar menjalankan agen logging yang dikonfigurasi untuk mengambil log dari aplikasi kontainer.
Kontainer streaming sidecar
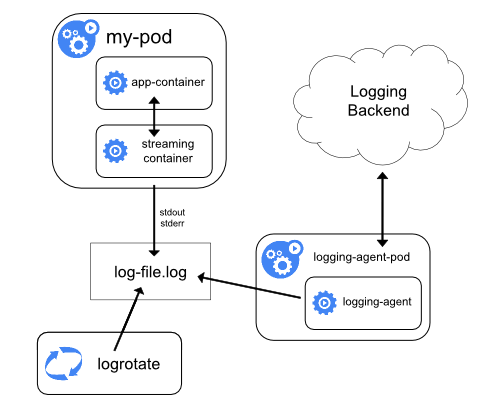
Kamu dapat memanfaatkan kubelet dan agen logging yang telah berjalan pada tiap node dengan menggunakan kontainer sidecar. Kontainer sidecar dapat membaca log dari sebuah berkas, socket atau journald. Tiap kontainer sidecar menuliskan log ke stdout atau stderr mereka sendiri.
Dengan menggunakan cara ini kamu dapat memisahkan aliran log dari bagian-bagian yang berbeda dari aplikasimu, yang beberapa mungkin tidak mendukung log ke stdout dan stderr. Perubahan logika aplikasimu dengan menggunakan cara ini cukup kecil, sehingga hampir tidak ada overhead. Selain itu, karena stdout dan stderr ditangani oleh kubelet, kamu juga dapat menggunakan alat bawaan seperti kubectl logs.
Sebagai contoh, sebuah pod berjalan pada satu kontainer tunggal, dan kontainer menuliskan ke dua berkas log yang berbeda, dengan dua format yang berbeda pula. Berikut ini file konfigurasi untuk Pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Hal ini akan menyulitkan untuk mengeluarkan log dalam format yang berbeda pada aliran log yang sama, meskipun kamu dapat me-redirect keduanya ke stdout dari kontainer. Sebagai gantinya, kamu dapat menggunakan dua buah kontainer sidecar. Tiap kontainer sidecar dapat membaca suatu berkas log tertentu dari shared volume kemudian mengarahkan log ke stdout-nya sendiri.
Berikut file konfigurasi untuk pod yang memiliki dua buah kontainer sidecard:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
Saat kamu menjalankan pod ini, kamu dapat mengakses tiap aliran log secara terpisah dengan menjalankan perintah berikut:
kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
Agen node-level yang terpasang di klastermu akan mengambil aliran log tersebut secara otomatis tanpa perlu melakukan konfigurasi tambahan. Bahkan jika kamu mau, kamu dapat mengonfigurasi agen untuk melakukan parse baris log tergantung dari kontainer sumber awalnya.
Sedikit catatan, meskipun menggunakan memori dan CPU yang cukup rendah (sekitar beberapa milicore untuk CPU dan beberapa megabytes untuk memori), penulisan log ke file kemudian mengalirkannya ke stdout dapat berakibat penggunaan disk yang lebih besar. Jika kamu memiliki aplikasi yang menuliskan ke file tunggal, umumnya lebih baik menggunakan /dev/stdout sebagai tujuan daripada menggunakan pendekatan dengan kontainer sidecar.
Kontainer sidecar juga dapat digunakan untuk melakukan rotasi berkas log yang tidak dapat dirotasi oleh aplikasi itu sendiri. Contoh dari pendekatan ini adalah sebuah kontainer kecil yang menjalankan rotasi log secara periodik. Namun, direkomendasikan untuk menggunakan stdout dan stderr secara langsung dan menyerahkan kebijakan rotasi dan retensi pada kubelet.
Kontainer sidecar dengan agen logging
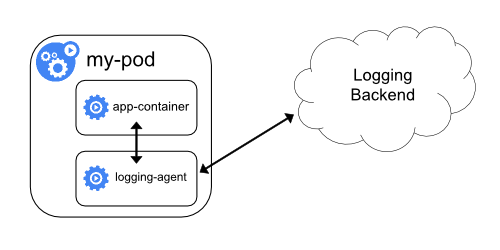
Jika agen node-level logging tidak cukup fleksible untuk kebutuhanmu, kamu dapat membuat kontainer sidecar dengan agen logging yang terpisah, yang kamu konfigurasi spesifik untuk berjalan dengan aplikasimu.
Catatan:
Menggunakan agen logging di dalam kontainer sidecar dapat berakibat penggunaan resource yang signifikan. Selain itu, kamu tidak dapat mengakses log itu dengan menggunakan perintahkubectl logs, karena mereka tidak dikontrol oleh kubelet.Sebagai contoh, kamu dapat menggunakan Stackdriver, yang menggunakan fluentd sebagai agen logging. Berikut ini dua file konfigurasi yang dapat kamu pakai untuk mengimplementasikan cara ini. File yang pertama berisi sebuah ConfigMap untuk mengonfigurasi fluentd.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Catatan:
Konfigurasi fluentd berada diluar cakupan artikel ini. Untuk informasi lebih lanjut tentang cara mengonfigurasi fluentd, silakan lihat dokumentasi resmi fluentd .File yang kedua mendeskripsikan sebuah pod yang memiliki kontainer sidecar yang menjalankan fluentd. Pod ini melakukan mount sebuah volume yang akan digunakan fluentd untuk mengambil data konfigurasinya.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Setelah beberapa saat, kamu akan mendapati pesan log pada interface Stackdriver.
Ingat, ini hanya contoh saja dan kamu dapat mengganti fluentd dengan agen logging lainnya, yang dapat membaca sumber apa saja dari dalam kontainer aplikasi.
Mengekspos log langsung dari aplikasi
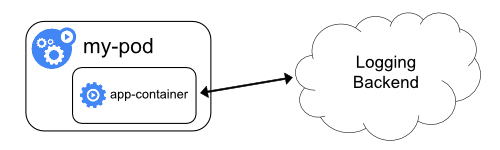
Kamu dapat mengimplementasikan klaster-level logging dengan mengekspos atau mengeluarkan log langsung dari tiap aplikasi; namun cara implementasi mekanisme logging tersebut diluar cakupan dari Kubernetes.
7 - Metrik untuk Komponen Sistem Kubernetes
Metrik dari komponen sistem dapat memberikan gambaran yang lebih baik tentang apa yang sedang terjadi di dalam sistem. Metrik sangat berguna untuk membuat dasbor (dashboard) dan peringatan (alert).
Komponen Kubernetes mengekspos metrik dalam format Prometheus. Format ini berupa teks biasa yang terstruktur, dirancang agar orang dan mesin dapat membacanya.
Metrik-metrik dalam Kubernetes
Dalam kebanyakan kasus, metrik tersedia pada endpoint /metrics dari server HTTP.
Untuk komponen yang tidak mengekspos endpoint secara bawaan, endpoint tersebut dapat diaktifkan
dengan menggunakan opsi --bind-address.
Contoh-contoh untuk komponen tersebut adalah:
Di dalam lingkungan produksi, kamu mungkin ingin mengonfigurasi Server Prometheus atau pengambil metrik (metrics scraper) lainnya untuk mengumpulkan metrik-metrik ini secara berkala dan membuatnya tersedia dalam semacam pangkalan data deret waktu (time series database).
Perlu dicatat bahwa kubelet
juga mengekspos metrik pada endpoint-endpoint seperti /metrics/cadvisor,
/metrics/resource dan /metrics/probes. Metrik-metrik tersebut tidak memiliki
siklus hidup yang sama.
Jika klastermu menggunakan RBAC,
maka membaca metrik memerlukan otorisasi melalui user, group, atau
ServiceAccount dengan ClusterRole yang memperbolehkan untuk mengakses /metrics.
Sebagai contoh:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
Siklus hidup metrik
Metrik alfa (alpha) → Metrik stabil → Metrik usang (deprecated) → Metrik tersembunyi → Metrik terhapus
Metrik alfa tidak memiliki jaminan stabilitas. Metrik ini dapat dimodifikasi atau dihapus kapan saja.
Metrik stabil dijamin tidak akan mengalami perubahan. Hal ini berarti:
- Metrik stabil tanpa penanda usang (deprecated signature) tidak akan dihapus ataupun diganti namanya
- Jenis metrik stabil tidak akan dimodifikasi
Metrik usang dijadwalkan untuk dihapus, tetapi masih tersedia untuk digunakan. Metrik ini mencakup anotasi versi di mana metrik ini dianggap menjadi usang.
Sebagai contoh:
-
Sebelum menjadi usang
# HELP some_counter this counts things # TYPE some_counter counter some_counter 0 -
Setelah menjadi usang
# HELP some_counter (Deprecated since 1.15.0) this counts things # TYPE some_counter counter some_counter 0
Metrik tersembunyi tidak lagi dipublikasikan untuk pengambilan metrik (scraping), tetapi masih tersedia untuk digunakan. Untuk menggunakan metrik tersembunyi, lihat bagian Menampilkan metrik tersembunyi.
Metrik yang terhapus tidak lagi dipublikasikan dan tidak dapat digunakan lagi.
Menampilkan metrik tersembunyi
Seperti yang dijelaskan di atas, admin dapat mengaktifkan metrik tersembunyi melalui opsi baris perintah pada biner (program) tertentu. Ini dimaksudkan untuk digunakan sebagai jalan keluar bagi admin jika mereka melewatkan migrasi metrik usang dalam rilis terakhir.
Opsi show-hidden-metrics-for-version menerima input versi yang kamu inginkan untuk menampilkan metrik usang dalam rilis tersebut. Versi tersebut dinyatakan sebagai x.y, di mana x adalah versi mayor, y adalah versi minor. Versi patch tidak diperlukan meskipun metrik dapat menjadi usang dalam rilis patch, alasannya adalah kebijakan penandaan metrik usang dijalankan terhadap rilis minor.
Opsi tersebut hanya dapat menerima input versi minor sebelumnya sebagai nilai. Semua metrik yang disembunyikan di versi sebelumnya akan dikeluarkan jika admin mengatur versi sebelumnya ke show-hidden-metrics-for-version. Versi yang terlalu lama tidak diperbolehkan karena melanggar kebijakan untuk metrik usang.
Ambil metrik A sebagai contoh, di sini diasumsikan bahwa A sudah menjadi usang di versi 1.n. Berdasarkan kebijakan metrik usang, kita dapat mencapai kesimpulan berikut:
- Pada rilis
1.n, metrik menjadi usang, dan dapat dikeluarkan secara bawaan. - Pada rilis
1.n+1, metrik disembunyikan secara bawaan dan dapat dikeluarkan dengan baris perintahshow-hidden-metrics-for-version=1.n. - Pada rilis
1.n+2, metrik harus dihapus dari codebase. Tidak ada jalan keluar lagi.
Jika kamu meningkatkan versi dari rilis 1.12 ke 1.13, tetapi masih bergantung pada metrik A yang usang di 1.12, kamu harus mengatur metrik tersembunyi melalui baris perintah: --show-hidden-metrics = 1.12 dan ingatlah untuk menghapus ketergantungan terhadap metrik ini sebelum meningkatkan versi rilis ke 1.14.
Menonaktifkan metrik akselerator
kubelet mengumpulkan metrik akselerator melalui cAdvisor. Untuk mengumpulkan metrik ini, untuk akselerator seperti GPU NVIDIA, kubelet membuka koneksi dengan driver GPU. Ini berarti untuk melakukan perubahan infrastruktur (misalnya, pemutakhiran driver), administrator klaster perlu menghentikan agen kubelet.
Pengumpulkan metrik akselerator sekarang menjadi tanggung jawab vendor dibandingkan kubelet. Vendor harus menyediakan sebuah kontainer untuk mengumpulkan metrik dan mengeksposnya ke layanan metrik (misalnya, Prometheus).
Gerbang fitur DisableAcceleratorUsageMetrics menonaktifkan metrik yang dikumpulkan oleh kubelet, dengan lini masa (timeline) untuk mengaktifkan fitur ini secara bawaan.
Metrik komponen
Metrik kube-controller-manager
Metrik controller manager memberikan gambaran penting tentang kinerja dan kesehatan controller manager. Metrik ini mencakup metrik runtime bahasa Go yang umum seperti jumlah go_routine dan metrik khusus pengontrol seperti latensi permintaan etcd atau latensi API Cloudprovider (AWS, GCE, OpenStack) yang dapat digunakan untuk mengukur kesehatan klaster.
Mulai dari Kubernetes 1.7, metrik Cloudprovider yang detail tersedia untuk operasi penyimpanan untuk GCE, AWS, Vsphere, dan OpenStack. Metrik ini dapat digunakan untuk memantau kesehatan operasi persistent volume.
Misalnya, untuk GCE metrik-metrik berikut ini dipanggil:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Metrik kube-scheduler
Kubernetes v1.20 [alpha]
Penjadwal mengekspos metrik opsional yang melaporkan sumber daya yang diminta dan limit yang diinginkan dari semua pod yang berjalan. Metrik ini dapat digunakan untuk membangun dasbor perencanaan kapasitas, mengevaluasi limit penjadwalan yang digunakan saat ini atau secara historis, dengan cepat mengidentifikasi beban kerja yang tidak dapat dijadwalkan karena kurangnya sumber daya, dan membandingkan permintaan sumber daya oleh pod dengan penggunaannya yang aktual.
kube-scheduler mengidentifikasi permintaan dan limit sumber daya yang dikonfigurasi untuk setiap Pod; jika permintaan atau limit bukan nol, kube-scheduler akan melaporkan deret waktu (timeseries) metrik. Deret waktu diberi label dengan:
- namespace
- nama pod
- node di mana pod dijadwalkan atau string kosong jika belum dijadwalkan
- prioritas
- penjadwal yang ditugaskan untuk pod itu
- nama dari sumber daya (misalnya,
cpu) - satuan dari sumber daya jika diketahui (misalnya,
cores)
Setelah pod selesai (memiliki restartPolicy Never atau OnFailure dan berada dalam fase pod Succeeded atau Failed, atau telah dihapus dan semua kontainer dalam keadaan Terminated) deret metrik tidak lagi dilaporkan karena penjadwal sekarang sudah dibebaskan untuk menjadwalkan pod lain untuk dijalankan. Metrik yang dibahas pada bagian ini dikenal sebagai kube_pod_resource_request dan kube_pod_resource_limit.
Metrik diekspos melalui endpoint HTTP /metrics/resources dan memerlukan otorisasi yang sama seperti endpoint /metrics
pada penjadwal. Kamu harus menggunakan opsi --show-hidden-metrics-for-version=1.20 untuk mengekspos metrik-metrik stabilitas alfa ini.
Selanjutnya
- Baca tentang format teks Prometheus untuk berbagai metrik
- Baca tentang kebijakan deprecation Kubernetes
8 - Konfigurasi Garbage Collection pada kubelet
Garbage collection merupakan fitur kubelet yang sangat bermanfaat, yang akan membersihkan image-image dan juga kontainer-kontainer yang tidak lagi digunakan. Kubelet akan melakukan garbage collection untuk kontainer setiap satu menit dan garbage collection untuk image setiap lima menit.
Perangkat garbage collection eksternal tidak direkomendasikan karena perangkat tersebut berpotensi merusak perilaku kubelet dengan menghilangkan kontainer-kontainer yang sebenarnya masih diperlukan.
Garbage Collection untuk Image
Kubernetes mengelola lifecycle untuk seluruh image melalui imageManager, dengan bantuan cadvisor.
Policy untuk melakukan garbage collection memperhatikan dua hal: HighThresholdPercent dan LowThresholdPercent.
Penggunaan disk yang melewati batas atas (high threshold) akan men-trigger garbage collection.
Garbage collection akan mulai menghapus dari image-image yang paling jarang digunakan (least recently used)
sampai menemui batas bawah (low threshold) kembali.
Garbage Collection untuk Kontainer
Policy untuk melakukan garbage collection pada kontainer memperhatikan tiga variabel yang ditentukan oleh pengguna (user-defined).
MinAge merupakan umur minimal dimana suatu kontainer dapat terkena garbage collection.
MaxPerPodContainer merupakan jumlah maksimum yang diperbolehkan untuk setiap pod (UID, container name) pair memiliki
kontainer-kontainer yang sudah mati (dead containers). MaxContainers merupakan jumlah maksimal total dari seluruh kontainer yang sudah mati.
Semua variabel ini dapat dinonaktifkan secara individual, dengan mengatur MinAge ke angka nol serta mengatur MaxPerPodContainer dan MaxContainers
ke angka di bawah nol.
Kubelet akan mengambil tindakan untuk kontainer-kontainer yang tidak dikenal, sudah dihapus, atau diluar batasan-batasan yang diatur
sebelumnya melalui flag. Kontainer-kontainer yang paling lama (tertua) biasanya akan dihapus terlebih dahulu. MaxPerPodContainer dan MaxContainer
berpotensi mengalami konflik satu sama lain pada situasi saat menjaga jumlah maksimal kontainer per pod (MaxPerPodContainer) akan melebihi
jumlah kontainer mati (dead containers) yang diperbolehkan (MaxContainers).
MaxPerPodContainer dapat diatur sedemikian rupa dalam situasi ini: Seburuk-buruhknya dengan melakukan downgrade MaxPerPodContainer ke angka 1
dan melakukan evict kontainer-kontainer yang paling lama. Selain itu, kontainer-kontainer milik Pod yang telah dihapus akan dihilangkan
saat umur mereka telah melebihi MinAge.
Kontainer-kontainer yang tidak dikelola oleh kubelet akan terbebas dari garbage collection.
Konfigurasi Pengguna
Para pengguna dapat mengatur threshold-threshold untuk melakukan tuning pada garbage collection image melalui flag-flag kubelet sebagai berikut:
image-gc-high-threshold, persentase dari penggunaan disk yang men-trigger proses garbage collection untuk image. Default-nya adalah 85%.image-gc-low-threshold, persentase dari penggunaan disk dimana garbage collection berusaha menghapus image. Default-nya adalah 80%.
Kami juga memperbolehkan para pengguna untuk menyesuaikan policy garbage collection melalui flag-flag kubelet sebagai berikut:
minimum-container-ttl-duration, umur minimal untuk setiap kontainer yang sudah selesai (finished) sebelum terkena garbage collection. Default-nya adalah 0 menit, yang berarti setiap kontainer yang telah selesai akan terkena garbage collection.maximum-dead-containers-per-container, jumlah maksimal dari kontainer-kontainer lama yang diperbolehkan ada secara global. Default-nya adalah -1, yang berarti tidak ada batasannya untuk global.
Kontainer-kontainer dapat berpotensi terkena garbage collection sebelum kegunaannya telah usang. Kontainer-kontainer
ini memliki log dan data lainnya yang bisa saja berguna saat troubleshoot. Sangat direkomendasikan untuk menetapkan
angka yang cukup besar pada maximum-dead-containers-per-container, untuk memperbolehkan paling tidak 1 kontainer mati
untuk dijaga (retained) per jumlah kontainer yang diharapkan. Angka yang lebih besar untuk maximum-dead-containers
juga direkomendasikan untuk alasan serupa.
Lihat isu ini untuk penjelasan lebih lanjut.
Deprecation
Beberapa fitur Garbage Collection pada kubelet di laman ini akan digantikan oleh fitur eviction nantinya, termasuk:
| Flag Existing | Flag Baru | Alasan |
|---|---|---|
--image-gc-high-threshold |
--eviction-hard atau --eviction-soft |
sinyal eviction yang ada (existing) dapat men-trigger garbage collection |
--image-gc-low-threshold |
--eviction-minimum-reclaim |
hal serupa dapat diperoleh dengan eviction reclaim |
--maximum-dead-containers |
deprecated saat log yang telah usang tersimpan di luar konteks kontainer | |
--maximum-dead-containers-per-container |
deprecated saat log yang telah usang tersimpan di luar konteks kontainer | |
--minimum-container-ttl-duration |
deprecated saat log yang telah usang tersimpan di luar konteks kontainer | |
--low-diskspace-threshold-mb |
--eviction-hard atau eviction-soft |
eviction memberi generalisasi threshold disk untuk resource-resource lainnya |
--outofdisk-transition-frequency |
--eviction-pressure-transition-period |
eviction memberi generalisasi transisi tekanan disk (disk pressure)untuk resource-resource lainnya |
Selanjutnya
Lihat Konfigurasi untuk Menangani Kehabisan Resource untuk penjelasan lebih lanjut.
9 - Berbagai Proxy di Kubernetes
Laman ini menjelaskan berbagai proxy yang ada di dalam Kubernetes.
Berbagai Jenis Proxy
Ada beberapa jenis proxy yang akan kamu temui saat menggunakan Kubernetes:
-
- dijalankan pada desktop pengguna atau di dalam sebuah Pod
- melakukan proxy dari alamat localhost ke apiserver Kubernetes
- dari klien menuju proxy menggunakan HTTP
- dari proxy menuju apiserver menggunakan HTTPS
- mencari lokasi apiserver
- menambahkan header autentikasi
-
- merupakan sebuah bastion yang ada di dalam apiserver
- menghubungkan pengguna di luar klaster ke alamat-alamat IP di dalam klaster yang tidak bisa terjangkau
- dijalankan bersama process-process apiserver
- dari klien menuju proxy menggunakan HTTPS (atau http jika dikonfigurasi pada apiserver)
- dari proxy menuju target menggunakan HTTP atau HTTPS, tergantung pilihan yang diambil oleh proxy melalui informasi yang ada
- dapat digunakan untuk menghubungi Node, Pod, atau Service
- melakukan load balancing saat digunakan untuk menjangkau sebuah Service
-
- dijalankan pada setiap Node
- melakukan proxy untuk UDP, TCP dan SCTP
- tidak mengerti HTTP
- menyediakan load balancing
- hanya digunakan untuk menjangkau berbagai Service
-
Sebuah Proxy/Load-balancer di depan satu atau banyak apiserver:
- keberadaan dan implementasinya bervariasi tergantung pada klaster (contohnya nginx)
- ada di antara seluruh klien dan satu/banyak apiserver
- jika ada beberapa apiserver, berfungsi sebagai load balancer
-
Cloud Load Balancer pada servis eksternal:
- disediakan oleh beberapa penyedia layanan cloud, seperti AWS ELB, Google Cloud Load Balancer
- dibuat secara otomatis ketika Service dari Kubernetes dengan tipe
LoadBalancer - biasanya hanya tersedia untuk UDP/TCP
- support untuk SCTP tergantung pada load balancer yang diimplementasikan oleh penyedia cloud
- implementasi bervariasi tergantung pada penyedia cloud
Pengguna Kubernetes biasanya hanya cukup perlu tahu tentang kubectl proxy dan apiserver proxy. Untuk proxy-proxy lain di luar ini, admin klaster biasanya akan memastikan konfigurasinya dengan benar.
Melakukan request redirect
Proxy telah menggantikan fungsi redirect. Redirect telah terdeprekasi.
10 - Metrik controller manager
Metrik controller manager memberikan informasi penting tentang kinerja dan kesehatan dari controller manager.
Tentang metrik controller manager
Metrik controller manager ini berfungsi untuk memberikan informasi penting tentang kinerja dan kesehatan dari controller manager. Metrik ini juga berisi tentang metrik umum dari runtime bahasa pemrograman Go seperti jumlah go_routine dan metrik spesifik dari controller seperti latensi dari etcd request atau latensi API dari penyedia layanan cloud (AWS, GCE, OpenStack) yang dapat digunakan untuk mengukur kesehatan dari klaster.
Mulai dari Kubernetes 1.7, metrik yang lebih mendetil tentang operasi penyimpanan dari penyedia layanan cloud juga telah tersedia. Metrik-metrik ini dapat digunakan untuk memonitor kesehatan dari operasi persistent volume.
Berikut merupakan contoh nama metrik yang disediakan GCE:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
Konfigurasi
Pada sebuah klaster, informasi metrik controller manager dapat diakses melalui http://localhost:10252/metrics
dari host tempat controller manager dijalankan.
Metrik ini dikeluarkan dalam bentuk format prometheus serta mudah untuk dibaca manusia.
Pada environment produksi, kamu mungkin juga ingin mengonfigurasi prometheus atau pengumpul metrik lainnya untuk mengumpulkan metrik-metrik ini secara berkala dalam bentuk basis data time series.
11 - Instalasi Add-ons
Add-ons berfungsi untuk menambah serta memperluas fungsionalitas dari Kubernetes.
Laman ini akan menjabarkan beberapa add-ons yang tersedia serta tautan instruksi bagaimana cara instalasi masing-masing add-ons.
Add-ons pada setiap bagian akan diurutkan secara alfabet - pengurutan ini tidak dilakukan berdasarkan status preferensi atau keunggulan.
Jaringan dan Policy Jaringan
- ACI menyediakan integrasi jaringan kontainer dan keamanan jaringan dengan Cisco ACI.
- Calico merupakan penyedia jaringan L3 yang aman dan policy jaringan.
- Canal menggabungkan Flannel dan Calico, menyediakan jaringan serta policy jaringan.
- Cilium merupakan plugin jaringan L3 dan policy jaringan yang dapat menjalankan policy HTTP/API/L7 secara transparan. Mendukung mode routing maupun overlay/encapsulation.
- CNI-Genie memungkinkan Kubernetes agar dapat terkoneksi dengan beragam plugin CNI, seperti Calico, Canal, Flannel, Romana, atau Weave dengan mulus.
- Contiv menyediakan jaringan yang dapat dikonfigurasi (native L3 menggunakan BGP, overlay menggunakan vxlan, klasik L2, dan Cisco-SDN/ACI) untuk berbagai penggunaan serta policy framework yang kaya dan beragam. Proyek Contiv merupakan proyek open source. Laman instalasi ini akan menjabarkan cara instalasi, baik untuk klaster dengan kubeadm maupun non-kubeadm.
- Contrail, yang berbasis dari Tungsten Fabric, merupakan sebuah proyek open source yang menyediakan virtualisasi jaringan multi-cloud serta platform manajemen policy. Contrail dan Tungsten Fabric terintegrasi dengan sistem orkestrasi lainnya seperti Kubernetes, OpenShift, OpenStack dan Mesos, serta menyediakan mode isolasi untuk mesin virtual (VM), kontainer/pod dan bare metal.
- Flannel merupakan penyedia jaringan overlay yang dapat digunakan pada Kubernetes.
- Knitter merupakan solusi jaringan yang mendukung multipel jaringan pada Kubernetes.
- Multus merupakan sebuah multi plugin agar Kubernetes mendukung multipel jaringan secara bersamaan sehingga dapat menggunakan semua plugin CNI (contoh: Calico, Cilium, Contiv, Flannel), ditambah pula dengan SRIOV, DPDK, OVS-DPDK dan VPP pada workload Kubernetes.
- NSX-T Container Plug-in (NCP) menyediakan integrasi antara VMware NSX-T dan orkestrator kontainer seperti Kubernetes, termasuk juga integrasi antara NSX-T dan platform CaaS/PaaS berbasis kontainer seperti Pivotal Container Service (PKS) dan OpenShift.
- Nuage merupakan platform SDN yang menyediakan policy-based jaringan antara Kubernetes Pods dan non-Kubernetes environment dengan monitoring visibilitas dan keamanan.
- Romana merupakan solusi jaringan Layer 3 untuk jaringan pod yang juga mendukung NetworkPolicy API. Instalasi Kubeadm add-on ini tersedia di sini.
- Weave Net menyediakan jaringan serta policy jaringan, yang akan membawa kedua sisi dari partisi jaringan, serta tidak membutuhkan basis data eksternal.
Service Discovery
- CoreDNS merupakan server DNS yang fleksibel, mudah diperluas yang dapat diinstal sebagai in-cluster DNS untuk pod.
Visualisasi & Kontrol
- Dashboard merupakan antarmuka web dasbor untuk Kubernetes.
- Weave Scope merupakan perangkat untuk visualisasi grafis dari kontainer, pod, service dll milikmu. Gunakan bersama dengan akun Weave Cloud atau host UI-mu sendiri.
Add-ons Terdeprekasi
Ada beberapa add-on lain yang didokumentasikan pada direktori deprekasi cluster/addons.
Add-on lain yang dipelihara dan dikelola dengan baik dapat ditulis di sini. Ditunggu PR-nya!
12 - Prioritas dan Kesetaraan API (API Priority and Fairness)
Kubernetes v1.18 [alpha]
Mengontrol perilaku server API dari Kubernetes pada situasi beban berlebih
merupakan tugas utama dari administrator klaster. kube-apiserver memiliki beberapa kontrol yang tersedia
(seperti opsi --max-request-inflight dan --max-mutating-request-inflight
pada baris perintah atau command-line) untuk membatasi jumlah pekerjaan luar biasa yang akan
diterima, untuk mencegah banjirnya permintaan masuk dari beban berlebih
yang berpotensi untuk menghancurkan server API. Namun opsi ini tidak cukup untuk memastikan
bahwa permintaan yang paling penting dapat diteruskan pada saat kondisi lalu lintas (traffic) yang cukup tinggi.
Fitur Prioritas dan Kesetaraan API atau API Priority and Fairness (APF) adalah alternatif untuk meningkatkan batasan max-inflight seperti yang disebutkan di atas. APF mengklasifikasi dan mengisolasi permintaan dengan cara yang lebih halus. Fitur ini juga memperkenalkan jumlah antrian yang terbatas, sehingga tidak ada permintaan yang ditolak pada saat terjadi lonjakan permintaan dalam waktu yang sangat singkat. Permintaan dibebaskan dari antrian dengan menggunakan teknik antrian yang adil (fair queuing) sehingga, sebagai contoh, perilaku buruk dari satu controller tidak seharusnya mengakibatkan controller yang lain menderita (meskipun pada tingkat prioritas yang sama).
Perhatian:
Permintaan yang diklasifikasikan sebagai "long running" - terutama watch - tidak mengikuti filter prioritas dan kesetaraan API. Dimana ini juga berlaku pada opsi--max-request-inflight tanpa mengaktifkan APF.Mengaktifkan prioritas dan kesetaraan API
Fitur APF dikontrol oleh sebuah gerbang fitur (feature gate)
dan fitur ini tidak diaktifkan secara bawaan. Silahkan lihat
gerbang fitur
untuk penjelasan umum tentang gerbang fitur dan bagaimana cara mengaktifkan dan menonaktifkannya.
Nama gerbang fitur untuk APF adalah "APIPriorityAndFairness".
Fitur ini melibatkan sebuah Grup API yang harus juga diaktifkan. Kamu bisa melakukan ini dengan
menambahkan opsi pada baris perintah berikut pada permintaan ke kube-apiserver kamu:
kube-apiserver \
--feature-gates=APIPriorityAndFairness=true \
--runtime-config=flowcontrol.apiserver.k8s.io/v1alpha1=true \
# …dan opsi-opsi lainnya seperti biasa
Opsi pada baris perintah --enable-priority-and-fairness=false akan menonaktifkan fitur
APF, bahkan ketika opsi yang lain telah mengaktifkannya.
Konsep
Ada beberapa fitur lainnya yang terlibat dalam fitur APF. Permintaan yang masuk diklasifikasikan berdasarkan atribut permintaan dengan menggunakan FlowSchema, dan diserahkan ke tingkat prioritas. Tingkat prioritas menambahkan tingkat isolasi dengan mempertahankan batas konkurensi yang terpisah, sehingga permintaan yang diserahkan ke tingkat prioritas yang berbeda tidak dapat membuat satu sama lain menderita. Dalam sebuah tingkat prioritas, algoritma fair-queuing mencegah permintaan dari flows yang berbeda akan memberikan penderitaan kepada yang lainnya, dan memperbolehkan permintaan untuk dimasukkan ke dalam antrian untuk mencegah pelonjakan lalu lintas yang akan menyebabkan gagalnya permintaan, walaupun pada saat beban rata-ratanya cukup rendah.
Tingkat prioritas (Priority Level)
Tanpa pengaktifan APF, keseluruhan konkurensi dalam
server API dibatasi oleh opsi pada kube-apiserver
--max-request-inflight dan --max-mutating-request-inflight. Dengan pengaktifan APF,
batas konkurensi yang ditentukan oleh opsi ini akan dijumlahkan dan kemudian jumlah tersebut dibagikan
untuk sekumpulan tingkat prioritas (priority level) yang dapat dikonfigurasi. Setiap permintaan masuk diserahkan
ke sebuah tingkat prioritas, dan setiap tingkat prioritas hanya akan meneruskan sebanyak mungkin
permintaan secara bersamaan sesuai dengan yang diijinkan dalam konfigurasi.
Konfigurasi bawaan, misalnya, sudah mencakup tingkat prioritas terpisah untuk permintaan dalam rangka pemilihan pemimpin (leader-election), permintaan dari controller bawaan, dan permintaan dari Pod. Hal ini berarti bahwa Pod yang berperilaku buruk, yang bisa membanjiri server API dengan permintaan, tidak akan mampu mencegah kesuksesan pemilihan pemimpin atau tindakan yang dilakukan oleh controller bawaan.
Antrian (Queuing)
Bahkan dalam sebuah tingkat prioritas mungkin akan ada sumber lalu lintas yang berbeda dalam jumlah besar. Dalam situasi beban berlebih, sangat penting untuk mencegah satu aliran permintaan dari penderitaan karena aliran yang lainnya (khususnya, dalam kasus yang relatif umum dari sebuah klien tunggal bermasalah (buggy) yang dapat membanjiri kube-apiserver dengan permintaan, klien bermasalah itu idealnya tidak memiliki banyak dampak yang bisa diukur terhadap klien yang lainnya). Hal ini ditangani dengan menggunakan algoritma fair-queuing untuk memproses permintaan yang diserahkan oleh tingkat prioritas yang sama. Setiap permintaan diserahkan ke sebuah flow, yang diidentifikasi berdasarkan nama FlowSchema yang sesuai, ditambah dengan flow distinguisher - yang bisa saja didasarkan pada pengguna yang meminta, sumber daya Namespace dari target, atau tidak sama sekali - dan sistem mencoba untuk memberikan bobot yang hampir sama untuk permintaan dalam flow yang berbeda dengan tingkat prioritas yang sama.
Setelah mengklasifikasikan permintaan ke dalam sebuah flow, fitur APF kemudian dapat menyerahkan permintaan ke dalam sebuah antrian. Penyerahan ini menggunakan teknik yang dikenal sebagai _shuffle sharding_, yang membuat penggunaan antrian yang relatif efisien untuk mengisolasi flow dengan intensitas rendah dari flow dengan intensitas tinggi.
Detail dari algoritma antrian dapat disesuaikan untuk setiap tingkat prioritas, dan memperbolehkan administrator untuk menukar (trade off) dengan penggunaan memori, kesetaraan (properti dimana flow yang independen akan membuat semua kemajuan ketika total dari lalu lintas sudah melebihi kapasitas), toleransi untuk lonjakan lalu lintas, dan penambahan latensi yang dihasilkan oleh antrian.
Permintaan yang dikecualikan (Exempt Request)
Beberapa permintaan dianggap cukup penting sehingga mereka tidak akan mengikuti salah satu batasan yang diberlakukan oleh fitur ini. Pengecualian ini untuk mencegah konfigurasi flow control yang tidak terkonfigurasi dengan baik sehingga tidak benar-benar menonaktifkan server API.
Bawaan (Default)
Fitur APF dikirimkan dengan konfigurasi yang disarankan dimana konfigurasi itu seharusnya cukup untuk bereksperimen; jika klaster kamu cenderung mengalami beban berat maka kamu harus mempertimbangkan konfigurasi apa yang akan bekerja paling baik. Kelompok konfigurasi yang disarankan untuk semua permintaan terbagi dalam lima prioritas kelas:
-
Tingkat prioritas
systemdiperuntukkan bagi permintaan dari grupsystem:nodes, mis. Kubelet, yang harus bisa menghubungi server API agar mendapatkan workload untuk dijadwalkan. -
Tingkat prioritas
leader-electiondiperuntukkan bagi permintaan dalam pemilihan pemimpin (leader election) dari controller bawaan (khususnya, permintaan untukendpoint,configmaps, atauleasesyang berasal darisystem:kube-controller-manageratau penggunasystem:kube-schedulerdan akun Service di Namespacekube-system). Hal ini penting untuk mengisolasi permintaan ini dari lalu lintas yang lain karena kegagalan dalam pemilihan pemimpin menyebabkan controller akan gagal dan memulai kembali (restart), yang pada akhirnya menyebabkan lalu lintas yang lebih mahal karena controller yang baru perlu menyinkronkan para informannya. -
Tingkat prioritas
workload-highdiperuntukkan bagi permintaan yang lain dari controller bawaan. -
Tingkat prioritas
workload-lowdiperuntukkan bagi permintaan dari akun Service yang lain, yang biasanya mencakup semua permintaan dari controller yang bekerja didalam Pod. -
Tingkat prioritas
global-defaultmenangani semua lalu lintas lainnya, mis. perintah interaktifkubectlyang dijalankan oleh pengguna yang tidak memiliki hak khusus.
Kemudian, ada dua PriorityLevelConfiguration dan dua FlowSchema yang telah dibangun dan tidak mungkin ditimpa ulang:
-
Tingkat prioritas khusus
exemptdiperuntukkan bagi permintaan yang tidak akan dikenakan flow control sama sekali: permintaan itu akan selalu diteruskan sesegera mungkin. FlowSchemaexemptkhusus mengklasifikasikan semua permintaan dari kelompoksystem:masterske dalam tingkat prioritas khusus ini. Kamu juga dapat menentukan FlowSchema lain yang mengarahkan permintaan lain ke tingkat prioritas ini juga, apabila permintaan tersebut sesuai. -
Tingkat prioritas khusus
catch-alldigunakan secara kombinasi dengan spesial FlowSchemacatch-alluntuk memastikan bahwa setiap permintaan mendapatkan proses klasifikasi. Biasanya kamu tidak harus bergantung pada konfigurasi catch-all ini, dan kamu seharusnya membuat FlowSchema catch-all dan PriorityLevelConfiguration kamu sendiri (atau gunakan konfigurasiglobal-defaultyang sudah diinstal secara bawaan) secara benar. Untuk membantu menemukan kesalahan konfigurasi yang akan melewatkan beberapa klasifikasi permintaan, maka tingkat prioritascatch-allhanya wajib mengijinkan satu konkurensi bersama dan tidak melakukan memasukkan permintaan dalam antrian, sehingga membuat lalu lintas yang secara relatif hanya sesuai dengan FlowSchemacatch-allakan ditolak dengan kode kesalahan HTTP 429.
Sumber daya (Resource)
Flow control API melibatkan dua jenis sumber daya. PriorityLevelConfiguration yang menentukan kelas isolasi yang tersedia, bagian dari konkurensi anggaran yang tersedia yang masing-masing dapat menangani bagian tersebut, dan memperbolehkan untuk melakukan fine-tuning terhadap perilaku antrian. FlowSchema yang digunakan untuk mengklasifikasikan permintaan individu yang masuk, mencocokkan masing-masing dengan setiap PriorityLevelConfiguration.
PriorityLevelConfiguration
Sebuah PriorityLevelConfiguration merepresentasikan sebuah kelas isolasi tunggal. Setiap PriorityLevelConfiguration memiliki batas independensi dalam hal jumlah permintaan yang belum diselesaikan, dan batasan dalam hal jumlah permintaan yang mengantri.
Batas konkurensi untuk PriorityLevelConfiguration tidak disebutkan dalam
jumlah permintaan secara mutlak, melainkan dalam "concurrency shares." Total batas konkurensi
untuk server API didistribusikan di antara PriorityLevelConfiguration yang ada
secara proporsional dengan "concurrency shares" tersebut. Ini mengizinkan seorang
administrator klaster untuk meningkatkan atau menurunkan jumlah total lalu lintas ke sebuah
server dengan memulai kembali kube-apiserver dengan nilai opsi
--max-request-inflight (atau --max-mutating-request-inflight) yang berbeda, dan semua
PriorityLevelConfiguration akan melihat konkurensi maksimum yang diizinkan kepadanya untuk menaikkan (atau
menurunkan) dalam fraksi yang sama.
Perhatian:
Dengan fitur Prioritas dan Kesetaraan yang diaktifkan, batas total konkurensi untuk server diatur pada nilai penjumlahan dari--max-request-inflight dan
--max-mutating-request-inflight. Tidak akan ada lagi perbedaan
antara permintaan yang bermutasi dan permintaan yang tidak bermutasi; jika kamu ingin melayaninya
secara terpisah untuk suatu sumber daya yang ada, maka perlu membuat FlowSchema terpisah yang sesuai dengan
masing-masing kata kerja dari permintaan yang bermutasi dan yang tidak bermutasi tersebut.Ketika jumlah permintaan masuk yang diserahkan kepada sebuah
PriorityLevelConfiguration melebihi dari tingkat konkurensi yang diizinkan,
bagian type dari spesifikasinya menentukan apa yang akan terjadi pada permintaan selanjutnya.
Tipe Reject berarti bahwa kelebihan lalu lintas akan segera ditolak
dengan kode kesalahan HTTP 429 (yang artinya terlalu banyak permintaan). Tipe Queue berarti permintaan
di atas batas tersebut akan mengantri, dengan teknik sharding shuffle dan fair queuing yang digunakan
untuk menyelaraskan kemajuan antara flow permintaan.
Konfigurasi antrian memungkinkan mengatur algoritma fair queuing untuk sebuah tingkat prioritas. Detail algoritma dapat dibaca di proposal pembaharuan, namun secara singkat:
-
Meningkatkan
queue(antrian) berarti mengurangi tingkat tabrakan antara flow yang berbeda, sehingga berakibat pada biaya untuk meningkatkan penggunaan memori. Nilai 1 di sini secara efektif menonaktifkan logika fair-queuing, tetapi masih mengizinkan permintaan untuk dimasukkan kedalam antrian. -
Meningkatkan
queueLengthLimitberarti memperbolehkan lonjakan yang lebih besar dari lalu lintas untuk berkelanjutan tanpa menggagalkan permintaan apa pun, dengan konsekuensi akan meningkatkan latensi dan penggunaan memori. -
Mengubah
handSizeberarti memperbolehkan kamu untuk menyesuaikan probabilitas tabrakan antara flow yang berbeda dan keseluruhan konkurensi yang tersedia untuk satu flow tunggal dalam situasi beban berlebih.Catatan:
`HandSize` yang lebih besar membuat dua _flow_ individual berpeluang kecil untuk bertabrakan (dan dimana _flow_ yang satu bisa membuat _flow_ yang lain menderita), tetapi akan lebih memungkinkan bahwa _flow_ dalam jumlah kecil akan dapat mendominasi apiserver. `HandSize` yang lebih besar juga berpotensi meningkatkan jumlah latensi yang diakibatkan oleh satu _flow_ lalu lintas tunggal yang tinggi. Jumlah maksimum permintaan dalam antrian yang diijinkan dari sebuah _flow_ tunggal adalah `handSize * queueLengthLimit`.
Berikut ini adalah tabel yang menunjukkan koleksi konfigurasi shuffle sharding yang menarik, dimana setiap probabilitas mouse (flow dengan intensitas rendah) yang diberikan akan dimampatkan oleh elephant (flow dengan intensitas tinggi) dalam sebuah koleksi ilustratif dari jumlah elephant yang berbeda. Silahkan lihat pada https://play.golang.org/p/Gi0PLgVHiUg, yang digunakan untuk menghitung nilai-nilai dalam tabel ini.
| HandSize | Queues | 1 elephant | 4 elephants | 16 elephants |
|---|---|---|---|---|
| 12 | 32 | 4.428838398950118e-09 | 0.11431348830099144 | 0.9935089607656024 |
| 10 | 32 | 1.550093439632541e-08 | 0.0626479840223545 | 0.9753101519027554 |
| 10 | 64 | 6.601827268370426e-12 | 0.00045571320990370776 | 0.49999929150089345 |
| 9 | 64 | 3.6310049976037345e-11 | 0.00045501212304112273 | 0.4282314876454858 |
| 8 | 64 | 2.25929199850899e-10 | 0.0004886697053040446 | 0.35935114681123076 |
| 8 | 128 | 6.994461389026097e-13 | 3.4055790161620863e-06 | 0.02746173137155063 |
| 7 | 128 | 1.0579122850901972e-11 | 6.960839379258192e-06 | 0.02406157386340147 |
| 7 | 256 | 7.597695465552631e-14 | 6.728547142019406e-08 | 0.0006709661542533682 |
| 6 | 256 | 2.7134626662687968e-12 | 2.9516464018476436e-07 | 0.0008895654642000348 |
| 6 | 512 | 4.116062922897309e-14 | 4.982983350480894e-09 | 2.26025764343413e-05 |
| 6 | 1024 | 6.337324016514285e-16 | 8.09060164312957e-11 | 4.517408062903668e-07 |
FlowSchema
FlowSchema mencocokkan beberapa permintaan yang masuk dan menetapkan permintaan ke dalam sebuah
tingkat prioritas. Setiap permintaan masuk diuji dengan setiap
FlowSchema secara bergiliran, dimulai dari yang terendah secara numerik ---
yang kita anggap sebagai yang tertinggi secara logis --- matchingPrecedence dan
begitu seterusnya. FlowSchema yang cocok pertama kali akan menang.
Perhatian:
Hanya FlowSchema yang pertama kali cocok untuk permintaan yang diberikan yang akan dianggap penting. Jika ada banyak FlowSchema yang cocok dengan sebuah permintaan masuk, maka akan ditetapkan berdasarkan salah satu yang mempunyaimatchingPrecedence tertinggi. Jika ada beberapa FlowSchema dengan nilai
matchingPrecedence yang sama dan cocok dengan permintaan yang sama juga, permintaan dengan leksikografis
name yang lebih kecil akan menang, tetapi akan lebih baik untuk tidak mengandalkan metode ini, dan sebaiknya
perlu memastikan bahwa tidak ada dua FlowSchema yang memiliki matchingPrecedence yang sama.Sebuah FlowSchema dianggap cocok dengan sebuah permintaan yang diberikan jika setidaknya salah satu dari rules nya
ada yang cocok. Sebuah aturan (rule) cocok jika setidaknya satu dari subject dan
ada salah satu dari resourceRules atau nonResourceRules (tergantung dari apakah permintaan
yang masuk adalah untuk URL sumber daya atau non-sumber daya) yang cocok dengan permintaan tersebut.
Untuk bagian name dalam subjek, dan bagian verbs, apiGroups, resources,
namespaces, dan nonResourceURLs dalam aturan sumber daya dan non-sumber daya,
wildcard * mungkin bisa ditetapkan untuk mencocokkan semua nilai pada bagian yang diberikan,
sehingga secara efektif menghapusnya dari pertimbangan.
Sebuah DistinguisherMethod.type dari FlowSchema menentukan bagaimana permintaan
yang cocok dengan Skema itu akan dipisahkan menjadi flow. Nilai tipe itu bisa jadi ByUser, dalam
hal ini satu pengguna yang meminta tidak akan bisa menghabiskan kapasitas dari pengguna lain,
atau bisa juga ByNamespace, dalam hal ini permintaan sumber daya
di salah satu Namespace tidak akan bisa menyebabkan penderitaan bagi permintaan akan sumber daya
dalam kapasitas Namespace yang lain, atau bisa juga kosong (atau distinguisherMethod
dihilangkan seluruhnya), dalam hal ini semua permintaan yang cocok dengan FlowSchema ini akan
dianggap sebagai bagian dari sebuah flow tunggal. Pilihan yang tepat untuk FlowSchema yang diberikan
akan bergantung pada sumber daya dan lingkungan khusus kamu.
Diagnosis
Setiap respons HTTP dari server API dengan fitur prioritas dan kesetaraan
yang diaktifkan memiliki dua header tambahan: X-Kubernetes-PF-FlowSchema-UID dan
X-Kubernetes-PF-PriorityLevel-UID, yang mencatat skema flow yang cocok dengan permintaan
dan tingkat prioritas masing-masing. Name Objek API tidak termasuk dalam header ini jika pengguna peminta tidak
memiliki izin untuk melihatnya, jadi ketika melakukan debugging kamu dapat menggunakan perintah seperti ini
kubectl get flowschema -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
kubectl get prioritylevelconfiguration -o custom-columns="uid:{metadata.uid},name:{metadata.name}"
untuk mendapatkan pemetaan UID ke names baik untuk FlowSchema maupun PriorityLevelConfiguration.
Observabilitas
Saat kamu mengaktifkan fitur Prioritas dan Kesetaraan API atau APF, kube-apiserver akan mengeluarkan metrik tambahan. Dengan memantau metrik ini dapat membantu kamu untuk menentukan apakah konfigurasi kamu tidak tepat dalam membatasi lalu lintas yang penting, atau menemukan beban kerja yang berperilaku buruk yang dapat membahayakan kesehatan dari sistem.
-
apiserver_flowcontrol_rejected_requests_totalmenghitung permintaan yang ditolak, mengelompokkannya berdasarkan nama dari tingkat prioritas yang ditetapkan, nama FlowSchema yang ditetapkan, dan alasan penolakan tersebut. Alasan penolakan akan mengambil dari salah satu alasan-alasan berikut:queue-full, yang mengindikasikan bahwa sudah terlalu banyak permintaan yang menunggu dalam antrian,concurrency-limit, yang mengindikasikan bahwa PriorityLevelConfiguration telah dikonfigurasi untuk menolak, bukan untuk memasukan permintaan berlebih ke dalam antrian, atautime-out, yang mengindikasikan bahwa permintaan masih dalam antrian ketika batas waktu antriannya telah berakhir.
-
apiserver_flowcontrol_dispatched_requests_totalmenghitung permintaan yang sudah mulai dieksekusi, mengelompokkannya berdasarkan nama dari tingkat prioritas yang ditetapkan, dan nama dari FlowSchema yang ditetapkan. -
apiserver_flowcontrol_current_inqueue_requestsmemberikan jumlah total sesaat secara instan dari permintaan dalam antrian (bukan yang dieksekusi), dan mengelompokkannya berdasarkan tingkat prioritas dan FlowSchema. -
apiserver_flowcontrol_current_executing_requestsmemberikan jumlah total yang instan dari permintaan yang dieksekusi, dan mengelompokkannya berdasarkan tingkat prioritas dan FlowSchema. -
apiserver_flowcontrol_request_queue_length_after_enqueuememberikan histogram dari panjang antrian untuk semua antrian yang ada, mengelompokkannya berdasarkan tingkat prioritas dan FlowSchema, berdasarkan pengambilan sampel oleh permintaan enqueued. Setiap permintaan yang mendapatkan antrian berkontribusi ke satu sampel dalam histogramnya, pelaporan panjang antrian dilakukan setelah permintaan yang mengantri tersebut ditambahkan. Perlu dicatat bahwa ini akan menghasilkan statistik yang berbeda dengan survei yang tidak bias.Catatan:
Nilai asing atau tidak biasa dalam histogram akan berarti ada kemungkinan sebuah _flow_ (misalnya, permintaan oleh satu pengguna atau untuk satu _namespace_, tergantung pada konfigurasinya) telah membanjiri server API, dan sedang dicekik. Sebaliknya, jika histogram dari satu tingkat prioritas menunjukkan bahwa semua antrian dalam prioritas level itu lebih panjang daripada level prioritas yang lainnya, mungkin akan sesuai untuk meningkatkan _concurrency shares_ dari PriorityLevelConfiguration itu. -
apiserver_flowcontrol_request_concurrency_limitmemberikan hasil perhitungan batas konkurensi (berdasarkan pada batas konkurensi total dari server API dan concurrency share dari PriorityLevelConfiguration) untuk setiap PriorityLevelConfiguration. -
apiserver_flowcontrol_request_wait_duration_secondsmemberikan histogram tentang bagaimana permintaan yang panjang dihabiskan dalam antrian, mengelompokkannya berdasarkan FlowSchema yang cocok dengan permintaan, tingkat prioritas yang ditetapkan, dan apakah permintaan tersebut berhasil dieksekusi atau tidak.Catatan:
Karena setiap FlowSchema selalu memberikan permintaan untuk satu PriorityLevelConfiguration, kamu dapat menambahkan histogram untuk semua FlowSchema dalam satu tingkat prioritas untuk mendapatkan histogram yang efektif dari permintaan yang ditetapkan ke tingkat prioritas tersebut. -
apiserver_flowcontrol_request_execution_secondsmemberikan histogram tentang bagaimana caranya permintaan yang panjang diambil untuk benar-benar dieksekusi, mengelompokkannya berdasarkan FlowSchema yang cocok dengan permintaan dan tingkat prioritas yang ditetapkan pada permintaan tersebut.
Selanjutnya
Untuk latar belakang informasi mengenai detail desain dari prioritas dan kesetaraan API, silahkan lihat proposal pembaharuan. Kamu juga dapat membuat saran dan permintaan akan fitur melalui SIG API Machinery.