这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
集群管理
关于创建和管理 Kubernetes 集群的底层细节。
集群管理概述面向任何创建和管理 Kubernetes 集群的读者人群。
我们假设你大概了解一些核心的 Kubernetes 概念 。
规划集群
查阅安装 中的指导,获取如何规划、建立以及配置 Kubernetes
集群的示例。本文所列的文章称为发行版 。
说明:
并非所有发行版都是被积极维护的。
请选择使用最近 Kubernetes 版本测试过的发行版。
在选择一个指南前,有一些因素需要考虑:
你是打算在你的计算机上尝试 Kubernetes,还是要构建一个高可用的多节点集群?
请选择最适合你需求的发行版。
你正在使用类似 Google Kubernetes Engine
这样的被托管的 Kubernetes 集群 , 还是管理你自己的集群 ?
你的集群是在本地 还是云(IaaS) 上?Kubernetes 不能直接支持混合集群。
作为代替,你可以建立多个集群。
如果你在本地配置 Kubernetes ,
需要考虑哪种网络模型 最适合。你的 Kubernetes 在裸机 上还是虚拟机(VM) 上运行?
你是想运行一个集群 ,还是打算参与开发 Kubernetes 项目代码 ?
如果是后者,请选择一个处于开发状态的发行版。
某些发行版只提供二进制发布版,但提供更多的选择。
让你自己熟悉运行一个集群所需的组件 。
管理集群
保护集群
保护 kubelet
可选集群服务
DNS 集成 描述了如何将一个 DNS
名解析到一个 Kubernetes service。记录和监控集群活动 阐述了 Kubernetes
的日志如何工作以及怎样实现。
1 - 节点关闭
在 Kubernetes 集群中,节点 可以按计划的体面方式关闭,
也可能因断电或其他某些外部原因被意外关闭。如果节点在关闭之前未被排空,则节点关闭可能会导致工作负载失败。
节点可以体面关闭 或非体面关闭 。
节点体面关闭
特性状态:
Kubernetes v1.21 [beta] (enabled by default: true)
kubelet 会尝试检测节点系统关闭事件并终止在节点上运行的所有 Pod。
在节点终止期间,kubelet 保证 Pod 遵从常规的
Pod 终止流程 ,
且不接受新的 Pod(即使这些 Pod 已经绑定到该节点)。
节点体面关闭特性依赖于 systemd,因为它要利用
systemd 抑制器锁 机制,
在给定的期限内延迟节点关闭。
节点体面关闭特性受 GracefulNodeShutdown
特性门控 控制,
在 1.21 版本中是默认启用的。
注意,默认情况下,下面描述的两个配置选项,shutdownGracePeriod 和
shutdownGracePeriodCriticalPods 都是被设置为 0 的,因此不会激活节点体面关闭功能。
要激活此功能特性,这两个 kubelet 配置选项要适当配置,并设置为非零值。
一旦 systemd 检测到或通知节点关闭,kubelet 就会在节点上设置一个
NotReady 状况,并将 reason 设置为 "node is shutting down"。
kube-scheduler 会重视此状况,不将 Pod 调度到受影响的节点上;
其他第三方调度程序也应当遵循相同的逻辑。这意味着新的 Pod 不会被调度到该节点上,
因此不会有新 Pod 启动。
如果检测到节点关闭正在进行中,kubelet 也会 在 PodAdmission
阶段拒绝 Pod,即使是该 Pod 带有 node.kubernetes.io/not-ready:NoSchedule
的容忍度 ,也不会在此节点上启动。
同时,当 kubelet 通过 API 在其 Node 上设置该状况时,kubelet
也开始终止在本地运行的所有 Pod。
在体面关闭节点过程中,kubelet 分两个阶段来终止 Pod:
终止在节点上运行的常规 Pod。
终止在节点上运行的关键 Pod 。
节点体面关闭的特性对应两个
KubeletConfiguration
shutdownGracePeriod:
指定节点应延迟关闭的总持续时间。这是 Pod 体面终止的时间总和,不区分常规 Pod
还是关键 Pod 。
shutdownGracePeriodCriticalPods:
在节点关闭期间指定用于终止关键 Pod
的持续时间。该值应小于 shutdownGracePeriod。
说明:
在某些情况下,节点终止过程会被系统取消(或者可能由管理员手动取消)。
无论哪种情况下,节点都将返回到 Ready 状态。然而,已经开始终止进程的
Pod 将不会被 kubelet 恢复,需要被重新调度。
例如,如果设置了 shutdownGracePeriod=30s 和 shutdownGracePeriodCriticalPods=10s,
则 kubelet 将延迟 30 秒关闭节点。
在关闭期间,将保留前 20(30 - 10)秒用于体面终止常规 Pod,
而保留最后 10 秒用于终止关键 Pod 。
说明:
当 Pod 在正常节点关闭期间被驱逐时,它们会被标记为关闭。
运行 kubectl get pods 时,被驱逐的 Pod 的状态显示为 Terminated。
并且 kubectl describe pod 表示 Pod 因节点关闭而被驱逐:
Reason: Terminated
Message: Pod was terminated in response to imminent node shutdown.
基于 Pod 优先级的节点体面关闭
特性状态:
Kubernetes v1.24 [beta] (enabled by default: true)
为了在节点体面关闭期间提供更多的灵活性,尤其是处理关闭期间的 Pod 排序问题,
节点体面关闭机制能够关注 Pod 的 PriorityClass 设置,前提是你已经在集群中启用了此功能特性。
此特性允许集群管理员基于 Pod
的优先级类(Priority Class)
显式地定义节点体面关闭期间 Pod 的处理顺序。
前文所述的节点体面关闭 特性能够分两个阶段关闭 Pod,
首先关闭的是非关键的 Pod,之后再处理关键 Pod。
如果需要显式地以更细粒度定义关闭期间 Pod 的处理顺序,需要一定的灵活度,
这时可以使用基于 Pod 优先级的体面关闭机制。
当节点体面关闭能够处理 Pod 优先级时,节点体面关闭的处理可以分为多个阶段,
每个阶段关闭特定优先级类的 Pod。可以配置 kubelet 按确切的阶段处理 Pod,
且每个阶段可以独立设置关闭时间。
假设集群中存在以下自定义的 Pod
优先级类 。
Pod 优先级类名称
Pod 优先级类数值
custom-class-a100000
custom-class-b10000
custom-class-c1000
regular/unset0
在 kubelet 配置 中,
shutdownGracePeriodByPodPriority 看起来可能是这样:
Pod 优先级类数值
关闭期限
100000
10 秒
10000
180 秒
1000
120 秒
0
60 秒
对应的 kubelet 配置 YAML 将会是:
shutdownGracePeriodByPodPriority :
- priority : 100000
shutdownGracePeriodSeconds : 10
- priority : 10000
shutdownGracePeriodSeconds : 180
- priority : 1000
shutdownGracePeriodSeconds : 120
- priority : 0
shutdownGracePeriodSeconds : 60
上面的表格表明,所有 priority 值大于等于 100000 的 Pod 停止期限只有 10 秒,
所有 priority 值介于 10000 和 100000 之间的 Pod 停止期限是 180 秒,
所有 priority 值介于 1000 和 10000 之间的 Pod 停止期限是 120 秒,
其他所有 Pod 停止期限是 60 秒。
用户不需要为所有的优先级类都设置数值。例如,你也可以使用下面这种配置:
Pod 优先级类数值
关闭期限
100000
300 秒
1000
120 秒
0
60 秒
在上面这个场景中,优先级类为 custom-class-b 的 Pod 会与优先级类为 custom-class-c
的 Pod 在关闭时按相同期限处理。
如果在特定的范围内不存在 Pod,则 kubelet 不会等待对应优先级范围的 Pod。
kubelet 会直接跳到下一个优先级数值范围进行处理。
如果此功能特性被启用,但没有提供配置数据,则不会出现排序操作。
使用此功能特性需要启用 GracefulNodeShutdownBasedOnPodPriority
特性门控 ,
并将 kubelet 配置
中的 shutdownGracePeriodByPodPriority 设置为期望的配置,
其中包含 Pod 的优先级类数值以及对应的关闭期限。
说明:
在节点体面关闭期间考虑 Pod 优先级的能力是作为 Kubernetes v1.23 中的 Alpha 功能引入的。
在 Kubernetes 1.31 中该功能是 Beta 版,默认启用。
kubelet 子系统中会生成 graceful_shutdown_start_time_seconds 和
graceful_shutdown_end_time_seconds 度量指标以便监视节点关闭行为。
处理节点非体面关闭
特性状态:
Kubernetes v1.28 [stable] (enabled by default: true)
节点关闭的操作可能无法被 kubelet 的节点关闭管理器检测到,
或是因为该命令没有触发 kubelet 所使用的抑制器锁机制,或是因为用户错误,
即 ShutdownGracePeriod 和 ShutdownGracePeriodCriticalPod 配置不正确。
请参考以上节点体面关闭 部分了解更多详细信息。
当某节点关闭但 kubelet 的节点关闭管理器未检测到这一事件时,
在那个已关闭节点上、属于 StatefulSet
的 Pod 将停滞于终止状态,并且不能移动到新的运行节点上。
这是因为已关闭节点上的 kubelet 已不存在,亦无法删除 Pod,
因此 StatefulSet 无法创建同名的新 Pod。
如果 Pod 使用了卷,则 VolumeAttachments 无法从原来的已关闭节点上删除,
因此这些 Pod 所使用的卷也无法挂接到新的运行节点上。
最终,那些以 StatefulSet 形式运行的应用无法正常工作。
如果原来的已关闭节点被恢复,kubelet 将删除 Pod,新的 Pod 将被在不同的运行节点上创建。
如果原来的已关闭节点没有被恢复,那些在已关闭节点上的 Pod 将永远滞留在终止状态。
为了缓解上述情况,用户可以手动将具有 NoExecute 或 NoSchedule 效果的
node.kubernetes.io/out-of-service 污点添加到节点上,标记其无法提供服务。
如果在 kube-controller-manager
上启用了 NodeOutOfServiceVolumeDetach
特性门控 ,
并且节点被污点标记为无法提供服务,如果节点 Pod 上没有设置对应的容忍度,
那么这样的 Pod 将被强制删除,并且该在节点上被终止的 Pod 将立即进行卷分离操作。
这样就允许那些在无法提供服务节点上的 Pod 能在其他节点上快速恢复。
在非体面关闭期间,Pod 分两个阶段终止:
强制删除没有匹配的 out-of-service 容忍度的 Pod。
立即对此类 Pod 执行分离卷操作。
说明:
在添加 node.kubernetes.io/out-of-service 污点之前,
应该验证节点已经处于关闭或断电状态(而不是在重新启动中)。
将 Pod 移动到新节点后,用户需要手动移除停止服务的污点,
并且用户要检查关闭节点是否已恢复,因为该用户是最初添加污点的用户。
存储超时强制解除挂接
在任何情况下,当 Pod 未能在 6 分钟内删除成功,如果节点当时不健康,
Kubernetes 将强制解除挂接正在被卸载的卷。
任何运行在使用了强制解除挂接卷的节点之上的工作负载,
都将违反 CSI 规范 ,
该规范指出 ControllerUnpublishVolume
"必须 在调用卷上的所有 NodeUnstageVolume 和 NodeUnpublishVolume 执行且成功后被调用"。
在这种情况下,相关节点上的卷可能会遇到数据损坏。
强制存储解除挂接行为是可选的;用户可以选择使用"非体面节点关闭"特性。
可以通过在 kube-controller-manager 中设置 disable-force-detach-on-timeout
配置字段来禁用超时时存储强制解除挂接。
禁用超时强制解除挂接特性意味着,托管在异常超过 6 分钟的节点上的卷将不会保留其关联的
VolumeAttachment 。
应用此设置后,仍然关联卷到不健康 Pod 必须通过上述非体面节点关闭 过程进行恢复。
接下来
了解更多以下信息:
2 - 证书
要了解如何为集群生成证书,参阅证书 。
3 - 集群网络系统
集群网络系统是 Kubernetes 的核心部分,但是想要准确了解它的工作原理可是个不小的挑战。
下面列出的是网络系统的的四个主要问题:
高度耦合的容器间通信:这个已经被 Pod
和 localhost 通信解决了。
Pod 间通信:这是本文档讲述的重点。
Pod 与 Service 间通信:涵盖在 Service 中。
外部与 Service 间通信:也涵盖在 Service 中。
Kubernetes 的宗旨就是在应用之间共享机器。
通常来说,共享机器需要两个应用之间不能使用相同的端口,但是在多个应用开发者之间
去大规模地协调端口是件很困难的事情,尤其是还要让用户暴露在他们控制范围之外的集群级别的问题上。
动态分配端口也会给系统带来很多复杂度 - 每个应用都需要设置一个端口的参数,
而 API 服务器还需要知道如何将动态端口数值插入到配置模块中,服务也需要知道如何找到对方等等。
与其去解决这些问题,Kubernetes 选择了其他不同的方法。
要了解 Kubernetes 网络模型,请参阅此处 。
Kubernetes IP 地址范围
Kubernetes 集群需要从以下组件中配置的可用地址范围中为 Pod、Service 和 Node 分配不重叠的 IP 地址:
网络插件配置为向 Pod 分配 IP 地址。
kube-apiserver 配置为向 Service 分配 IP 地址。
kubelet 或 cloud-controller-manager 配置为向 Node 分配 IP 地址。
集群网络类型
根据配置的 IP 协议族,Kubernetes 集群可以分为以下几类:
仅 IPv4:网络插件、kube-apiserver 和 kubelet/cloud-controller-manager 配置为仅分配 IPv4 地址。
仅 IPv6:网络插件、kube-apiserver 和 kubelet/cloud-controller-manager 配置为仅分配 IPv6 地址。
IPv4/IPv6 或 IPv6/IPv4 双协议栈 :
网络插件配置为分配 IPv4 和 IPv6 地址。
kube-apiserver 配置为分配 IPv4 和 IPv6 地址。
kubelet 或 cloud-controller-manager 配置为分配 IPv4 和 IPv6 地址。
所有组件必须就配置的主要 IP 协议族达成一致。
Kubernetes 集群只考虑 Pod、Service 和 Node 对象中存在的 IP 协议族,而不考虑所表示对象的现有 IP。
例如,服务器或 Pod 的接口上可以有多个 IP 地址,但只有 node.status.addresses 或 pod.status.ips
中的 IP 地址被认为是实现 Kubernetes 网络模型和定义集群类型的。
如何实现 Kubernetes 的网络模型
网络模型由各节点上的容器运行时来实现。最常见的容器运行时使用
Container Network Interface (CNI) 插件来管理其网络和安全能力。
来自不同供应商 CNI 插件有很多。其中一些仅提供添加和删除网络接口的基本功能,
而另一些则提供更复杂的解决方案,例如与其他容器编排系统集成、运行多个 CNI 插件、高级 IPAM 功能等。
请参阅此页面 了解
Kubernetes 支持的网络插件的非详尽列表。
接下来
网络模型的早期设计、运行原理都在联网设计文档 里有详细描述。
关于未来的计划,以及旨在改进 Kubernetes 联网能力的一些正在进行的工作,可以参考 SIG Network
的 KEPs 。
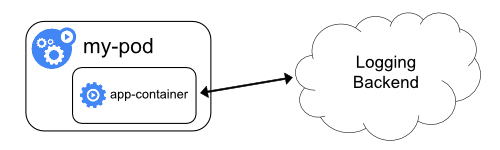
4 - 日志架构
应用日志可以让你了解应用内部的运行状况。日志对调试问题和监控集群活动非常有用。
大部分现代化应用都有某种日志记录机制。同样地,容器引擎也被设计成支持日志记录。
针对容器化应用,最简单且最广泛采用的日志记录方式就是写入标准输出和标准错误流。
但是,由容器引擎或运行时提供的原生功能通常不足以构成完整的日志记录方案。
例如,如果发生容器崩溃、Pod 被逐出或节点宕机等情况,你可能想访问应用日志。
在集群中,日志应该具有独立的存储,并且其生命周期与节点、Pod 或容器的生命周期相独立。
这个概念叫集群级的日志 。
集群级日志架构需要一个独立的后端用来存储、分析和查询日志。
Kubernetes 并不为日志数据提供原生的存储解决方案。
相反,有很多现成的日志方案可以集成到 Kubernetes 中。
下面各节描述如何在节点上处理和存储日志。
Pod 和容器日志
Kubernetes 从正在运行的 Pod 中捕捉每个容器的日志。
此示例使用带有一个容器的 Pod 的清单,该容器每秒将文本写入标准输出一次。
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox:1.28
args : [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done' ]
要运行此 Pod,请执行以下命令:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
输出为:
要获取这些日志,请执行以下 kubectl logs 命令:
输出类似于:
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
你可以使用 kubectl logs --previous 从容器的先前实例中检索日志。
如果你的 Pod 有多个容器,请如下通过将容器名称追加到该命令并使用 -c
标志来指定要访问哪个容器的日志:
kubectl logs counter -c count
详见 kubectl logs 文档
节点的容器日志处理方式
容器运行时对写入到容器化应用程序的 stdout 和 stderr 流的所有输出进行处理和转发。
不同的容器运行时以不同的方式实现这一点;不过它们与 kubelet 的集成都被标准化为 CRI 日志格式 。
默认情况下,如果容器重新启动,kubelet 会保留一个终止的容器及其日志。
如果一个 Pod 被逐出节点,所对应的所有容器及其日志也会被逐出。
kubelet 通过 Kubernetes API 的特殊功能将日志提供给客户端访问。
访问这个日志的常用方法是运行 kubectl logs。
日志轮转
特性状态:
Kubernetes v1.21 [stable]
kubelet 负责轮换容器日志并管理日志目录结构。
kubelet(使用 CRI)将此信息发送到容器运行时,而运行时则将容器日志写到给定位置。
你可以使用 kubelet 配置文件 配置两个
kubelet 配置选项 、
containerLogMaxSize (默认 10Mi)和 containerLogMaxFiles(默认 5)。
这些设置分别允许你分别配置每个日志文件大小的最大值和每个容器允许的最大文件数。
为了在工作负载生成的日志量较大的集群中执行高效的日志轮换,kubelet
还提供了一种机制,基于可以执行多少并发日志轮换以及监控和轮换日志所需要的间隔来调整日志的轮换方式。
你可以使用 kubelet 配置文件
配置两个 kubelet 配置选项 :
containerLogMaxWorkers 和 containerLogMonitorInterval。
当类似于基本日志示例一样运行 kubectl logs
说明:
只有最新的日志文件的内容可以通过 kubectl logs 获得。
例如,如果 Pod 写入 40 MiB 的日志,并且 kubelet 在 10 MiB 之后轮转日志,
则运行 kubectl logs 将最多返回 10 MiB 的数据。
系统组件日志
系统组件有两种类型:通常在容器中运行的组件和直接参与容器运行的组件。例如:
kubelet 和容器运行时不在容器中运行。kubelet 运行你的容器
(一起按 Pod 分组)
Kubernetes 调度器、控制器管理器和 API 服务器在 Pod 中运行
(通常是静态 Pod 。
etcd 组件在控制平面中运行,最常见的也是作为静态 Pod。
如果你的集群使用 kube-proxy,则通常将其作为 DaemonSet 运行。
日志位置
kubelet 和容器运行时写入日志的方式取决于节点使用的操作系统:
在使用 systemd 的 Linux 节点上,kubelet 和容器运行时默认写入 journald。
你要使用 journalctl 来阅读 systemd 日志;例如:journalctl -u kubelet。
如果 systemd 不存在,kubelet 和容器运行时将写入到 /var/log 目录中的 .log 文件。
如果你想将日志写入其他地方,你可以通过辅助工具 kube-log-runner 间接运行 kubelet,
并使用该工具将 kubelet 日志重定向到你所选择的目录。
默认情况下,kubelet 指示你的容器运行时将日志写入 /var/log/pods 中的目录。
有关 kube-log-runner 的更多信息,请阅读系统日志 。
默认情况下,kubelet 将日志写入目录 C:\var\logs 中的文件(注意这不是 C:\var\log)。
尽管 C:\var\log 是这些日志的 Kubernetes 默认位置,
但一些集群部署工具会将 Windows 节点设置为将日志放到 C:\var\log\kubelet。
如果你想将日志写入其他地方,你可以通过辅助工具 kube-log-runner 间接运行 kubelet,
并使用该工具将 kubelet 日志重定向到你所选择的目录。
但是,kubelet 默认指示你的容器运行时在目录 C:\var\log\pods 中写入日志。
有关 kube-log-runner 的更多信息,请阅读系统日志 。
对于在 Pod 中运行的 Kubernetes 集群组件,其日志会写入 /var/log 目录中的文件,
相当于绕过默认的日志机制(组件不会写入 systemd 日志)。
你可以使用 Kubernetes 的存储机制将持久存储映射到运行该组件的容器中。
kubelet 允许将 Pod 日志目录从默认的 /var/log/pods 更改为自定义路径。
可以通过在 kubelet 的配置文件中配置 podLogsDir 参数来进行此调整。
注意:
需要注意的是,默认位置 /var/log/pods 已使用很长一段时间,并且某些进程可能会隐式使用此路径。
因此,更改此参数必须谨慎,并自行承担风险。
另一个需要留意的问题是 kubelet 支持日志写入位置与 /var 位于同一磁盘上。
否则,如果日志位于与 /var 不同的文件系统上,kubelet
将不会跟踪该文件系统的使用情况。如果文件系统已满,则可能会出现问题。
有关 etcd 及其日志的详细信息,请查阅 etcd 文档 。
同样,你可以使用 Kubernetes 的存储机制将持久存储映射到运行该组件的容器中。
说明:
如果你部署 Kubernetes 集群组件(例如调度器)以将日志记录到从父节点共享的卷中,
则需要考虑并确保这些日志被轮转。Kubernetes 不管理这种日志轮转 。
你的操作系统可能会自动实现一些日志轮转。例如,如果你将目录 /var/log 共享到一个组件的静态 Pod 中,
则节点级日志轮转会将该目录中的文件视同为 Kubernetes 之外的组件所写入的文件。
一些部署工具会考虑日志轮转并将其自动化;而其他一些工具会将此留给你来处理。
集群级日志架构
虽然 Kubernetes 没有为集群级日志记录提供原生的解决方案,但你可以考虑几种常见的方法。
以下是一些选项:
使用在每个节点上运行的节点级日志记录代理。
在应用程序的 Pod 中,包含专门记录日志的边车(Sidecar)容器。
将日志直接从应用程序中推送到日志记录后端。
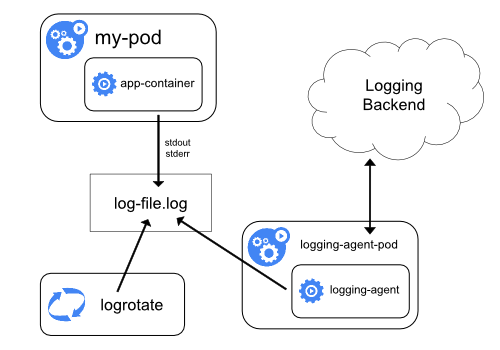
使用节点级日志代理
你可以通过在每个节点上使用节点级的日志记录代理 来实现集群级日志记录。
日志记录代理是一种用于暴露日志或将日志推送到后端的专用工具。
通常,日志记录代理程序是一个容器,它可以访问包含该节点上所有应用程序容器的日志文件的目录。
由于日志记录代理必须在每个节点上运行,推荐以 DaemonSet 的形式运行该代理。
节点级日志在每个节点上仅创建一个代理,不需要对节点上的应用做修改。
容器向标准输出和标准错误输出写出数据,但在格式上并不统一。
节点级代理收集这些日志并将其进行转发以完成汇总。
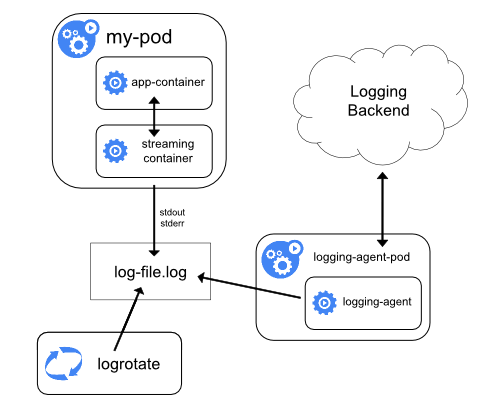
使用边车容器运行日志代理
你可以通过以下方式之一使用边车(Sidecar)容器:
边车容器将应用程序日志传送到自己的标准输出。
边车容器运行一个日志代理,配置该日志代理以便从应用容器收集日志。
传输数据流的边车容器
利用边车容器,写入到自己的 stdout 和 stderr 传输流,
你就可以利用每个节点上的 kubelet 和日志代理来处理日志。
边车容器从文件、套接字或 journald 读取日志。
每个边车容器向自己的 stdout 和 stderr 流中输出日志。
这种方法允许你将日志流从应用程序的不同部分分离开,其中一些可能缺乏对写入
stdout 或 stderr 的支持。重定向日志背后的逻辑是最小的,因此它的开销不大。
另外,因为 stdout 和 stderr 由 kubelet 处理,所以你可以使用内置的工具 kubectl logs。
例如,某 Pod 中运行一个容器,且该容器使用两个不同的格式写入到两个不同的日志文件。
下面是这个 Pod 的清单:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox:1.28
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
volumes :
- name : varlog
emptyDir : {}
不建议在同一个日志流中写入不同格式的日志条目,即使你成功地将其重定向到容器的 stdout 流。
相反,你可以创建两个边车容器。每个边车容器可以从共享卷跟踪特定的日志文件,
并将文件内容重定向到各自的 stdout 流。
下面是运行两个边车容器的 Pod 的清单:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox:1.28
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-log-1
image : busybox:1.28
args : [/bin/sh, -c, 'tail -n+1 -F /var/log/1.log']
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-log-2
image : busybox:1.28
args : [/bin/sh, -c, 'tail -n+1 -F /var/log/2.log']
volumeMounts :
- name : varlog
mountPath : /var/log
volumes :
- name : varlog
emptyDir : {}
现在当你运行这个 Pod 时,你可以运行如下命令分别访问每个日志流:
kubectl logs counter count-log-1
输出类似于:
0: Fri Apr 1 11:42:26 UTC 2022
1: Fri Apr 1 11:42:27 UTC 2022
2: Fri Apr 1 11:42:28 UTC 2022
...
kubectl logs counter count-log-2
输出类似于:
Fri Apr 1 11:42:29 UTC 2022 INFO 0
Fri Apr 1 11:42:30 UTC 2022 INFO 0
Fri Apr 1 11:42:31 UTC 2022 INFO 0
...
如果你在集群中安装了节点级代理,由代理自动获取上述日志流,而无需任何进一步的配置。
如果你愿意,你可以将代理配置为根据源容器解析日志行。
即使对于 CPU 和内存使用率较低的 Pod(CPU 为几毫核,内存为几兆字节),将日志写入一个文件,
将这些日志流写到 stdout 也有可能使节点所需的存储量翻倍。
如果你有一个写入特定文件的应用程序,则建议将 /dev/stdout 设置为目标文件,而不是采用流式边车容器方法。
边车容器还可用于轮转应用程序本身无法轮转的日志文件。
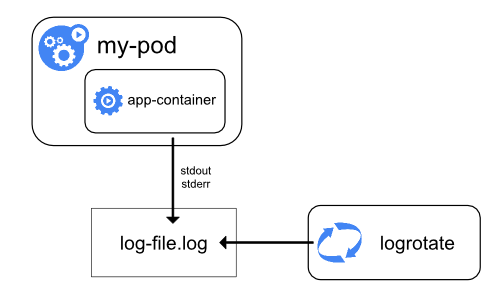
这种方法的一个例子是定期运行 logrotate 的小容器。
但是,直接使用 stdout 和 stderr 更直接,而将轮转和保留策略留给 kubelet。
集群中安装的节点级代理会自动获取这些日志流,而无需进一步配置。
如果你愿意,你也可以配置代理程序来解析源容器的日志行。
注意,尽管 CPU 和内存使用率都很低(以多个 CPU 毫核指标排序或者按内存的兆字节排序),
向文件写日志然后输出到 stdout 流仍然会成倍地增加磁盘使用率。
如果你的应用向单一文件写日志,通常最好设置 /dev/stdout 作为目标路径,
而不是使用流式的边车容器方式。
如果应用程序本身不能轮转日志文件,则可以通过边车容器实现。
这种方式的一个例子是运行一个小的、定期轮转日志的容器。
然而,还是推荐直接使用 stdout 和 stderr,将日志的轮转和保留策略交给 kubelet。
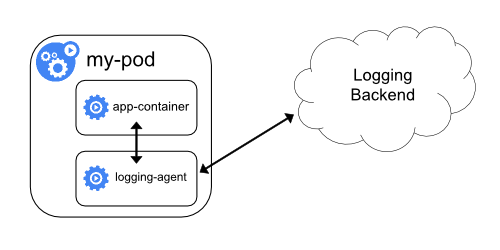
具有日志代理功能的边车容器
如果节点级日志记录代理程序对于你的场景来说不够灵活,
你可以创建一个带有单独日志记录代理的边车容器,将代理程序专门配置为与你的应用程序一起运行。
说明:
在边车容器中使用日志代理会带来严重的资源损耗。
此外,你不能使用 kubectl logs 访问日志,因为日志并没有被 kubelet 管理。
下面是两个配置文件,可以用来实现一个带日志代理的边车容器。
第一个文件包含用来配置 fluentd 的
ConfigMap 。
apiVersion : v1
kind : ConfigMap
metadata :
name : fluentd-config
data :
fluentd.conf : |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
说明:
你可以将此示例配置中的 fluentd 替换为其他日志代理,从应用容器内的其他来源读取数据。
第二个清单描述了一个运行 fluentd 边车容器的 Pod。
该 Pod 挂载一个卷,flutend 可以从这个卷上拣选其配置数据。
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox:1.28
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-agent
image : registry.k8s.io/fluentd-gcp:1.30
env :
- name : FLUENTD_ARGS
value : -c /etc/fluentd-config/fluentd.conf
volumeMounts :
- name : varlog
mountPath : /var/log
- name : config-volume
mountPath : /etc/fluentd-config
volumes :
- name : varlog
emptyDir : {}
- name : config-volume
configMap :
name : fluentd-config
从应用中直接暴露日志目录
从各个应用中直接暴露和推送日志数据的集群日志机制已超出 Kubernetes 的范围。
接下来
5 - Kubernetes 系统组件指标
通过系统组件指标可以更好地了解系统组个内部发生的情况。系统组件指标对于构建仪表板和告警特别有用。
Kubernetes 组件以
Prometheus 格式 生成度量值。
这种格式是结构化的纯文本,旨在使人和机器都可以阅读。
Kubernetes 中组件的指标
在大多数情况下,可以通过 HTTP 访问组件的 /metrics 端点来获取组件的度量值。
对于那些默认情况下不暴露端点的组件,可以使用 --bind-address 标志启用。
这些组件的示例:
在生产环境中,你可能需要配置 Prometheus 服务器 或
某些其他指标搜集器以定期收集这些指标,并使它们在某种时间序列数据库中可用。
请注意,kubelet 还会在 /metrics/cadvisor,
/metrics/resource 和 /metrics/probes 端点中公开度量值。这些度量值的生命周期各不相同。
如果你的集群使用了 RBAC ,
则读取指标需要通过基于用户、组或 ServiceAccount 的鉴权,要求具有允许访问
/metrics 的 ClusterRole。
例如:
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : prometheus
rules :
- nonResourceURLs :
- "/metrics"
verbs :
- get
指标生命周期
Alpha 指标 → 稳定的指标 → 弃用的指标 → 隐藏的指标 → 删除的指标
Alpha 指标没有稳定性保证。这些指标可以随时被修改或者删除。
稳定的指标可以保证不会改变。这意味着:
稳定的、不包含已弃用(deprecated)签名的指标不会被删除(或重命名)
稳定的指标的类型不会被更改
已弃用的指标最终将被删除,不过仍然可用。
这类指标包含注解,标明其被废弃的版本。
例如:
隐藏的指标不会再被发布以供抓取,但仍然可用。
要使用隐藏指标,请参阅显式隐藏指标 节。
删除的指标不再被发布,亦无法使用。
显示隐藏指标
如上所述,管理员可以通过设置可执行文件的命令行参数来启用隐藏指标,
如果管理员错过了上一版本中已经弃用的指标的迁移,则可以把这个用作管理员的逃生门。
show-hidden-metrics-for-version 标志接受版本号作为取值,版本号给出
你希望显示该发行版本中已弃用的指标。
版本表示为 x.y,其中 x 是主要版本,y 是次要版本。补丁程序版本不是必须的,
即使指标可能会在补丁程序发行版中弃用,原因是指标弃用策略规定仅针对次要版本。
该参数只能使用前一个次要版本。如果管理员将先前版本设置为 show-hidden-metrics-for-version,
则先前版本中隐藏的度量值会再度生成。不允许使用过旧的版本,因为那样会违反指标弃用策略。
以指标 A 为例,此处假设 A 在 1.n 中已弃用。根据指标弃用策略,我们可以得出以下结论:
在版本 1.n 中,这个指标已经弃用,且默认情况下可以生成。
在版本 1.n+1 中,这个指标默认隐藏,可以通过命令行参数 show-hidden-metrics-for-version=1.n 来再度生成。
在版本 1.n+2 中,这个指标就将被从代码中移除,不会再有任何逃生窗口。
如果你要从版本 1.12 升级到 1.13,但仍依赖于 1.12 中弃用的指标 A,则应通过命令行设置隐藏指标:
--show-hidden-metrics=1.12,并记住在升级到 1.14 版本之前删除此指标依赖项。
组件指标
kube-controller-manager 指标
控制器管理器指标可提供有关控制器管理器性能和运行状况的重要洞察。
这些指标包括通用的 Go 语言运行时指标(例如 go_routine 数量)和控制器特定的度量指标,
例如可用于评估集群运行状况的 etcd 请求延迟或云提供商(AWS、GCE、OpenStack)的 API 延迟等。
从 Kubernetes 1.7 版本开始,详细的云提供商指标可用于 GCE、AWS、Vsphere 和 OpenStack 的存储操作。
这些指标可用于监控持久卷操作的运行状况。
比如,对于 GCE,这些指标称为:
cloudprovider_gce_api_request_duration_seconds { request = "instance_list"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_insert"}
cloudprovider_gce_api_request_duration_seconds { request = "disk_delete"}
cloudprovider_gce_api_request_duration_seconds { request = "attach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "detach_disk"}
cloudprovider_gce_api_request_duration_seconds { request = "list_disk"}
kube-scheduler 指标
特性状态:
Kubernetes v1.21 [beta]
调度器会暴露一些可选的指标,报告所有运行中 Pod 所请求的资源和期望的约束值。
这些指标可用来构造容量规划监控面板、访问调度约束的当前或历史数据、
快速发现因为缺少资源而无法被调度的负载,或者将 Pod 的实际资源用量与其请求值进行比较。
kube-scheduler 组件能够辩识各个 Pod 所配置的资源
请求和约束 。
在 Pod 的资源请求值或者约束值非零时,kube-scheduler 会以度量值时间序列的形式
生成报告。该时间序列值包含以下标签:
名字空间
Pod 名称
Pod 调度所处节点,或者当 Pod 未被调度时用空字符串表示
优先级
为 Pod 所指派的调度器
资源的名称(例如,cpu)
资源的单位,如果知道的话(例如,cores)
一旦 Pod 进入完成状态(其 restartPolicy 为 Never 或 OnFailure,且
其处于 Succeeded 或 Failed Pod 阶段,或者已经被删除且所有容器都具有
终止状态),该时间序列停止报告,因为调度器现在可以调度其它 Pod 来执行。
这两个指标称作 kube_pod_resource_request 和 kube_pod_resource_limit。
指标暴露在 HTTP 端点 /metrics/resources,与调度器上的 /metrics 端点
一样要求相同的访问授权。你必须使用
--show-hidden-metrics-for-version=1.20 标志才能暴露那些稳定性为 Alpha
的指标。
禁用指标
你可以通过命令行标志 --disabled-metrics 来关闭某指标。
在例如某指标会带来性能问题的情况下,这一操作可能是有用的。
标志的参数值是一组被禁止的指标(例如:--disabled-metrics=metric1,metric2)。
指标顺序性保证
具有无限维度的指标可能会在其监控的组件中引起内存问题。
为了限制资源使用,你可以使用 --allow-metric-labels 命令行选项来为指标动态配置允许的标签值列表。
在 Alpha 阶段,此选项只能接受一组映射值作为可以使用的指标标签。
每个映射值的格式为<指标名称>,<标签名称>=<可用标签列表>,其中
<可用标签列表> 是一个用逗号分隔的、可接受的标签名的列表。
最终的格式看起来会是这样:
--allow-metric-labels <指标名称>,<标签名称>='<可用值1>,<可用值2>...', <指标名称2>,<标签名称>='<可用值1>, <可用值2>...', ...
下面是一个例子:
--allow-metric-labels number_count_metric,odd_number='1,3,5', number_count_metric,even_number='2,4,6', date_gauge_metric,weekend='Saturday,Sunday'
除了从 CLI 中指定之外,还可以在配置文件中完成此操作。
你可以使用组件的 --allow-metric-labels-manifest 命令行参数指定该配置文件的路径。
以下是该配置文件的内容示例:
"metric1,label2": "v1,v2,v3"
"metric2,label1": "v1,v2,v3"
此外,cardinality_enforcement_unexpected_categorizations_total
元指标记录基数执行期间意外分类的计数,即每当遇到允许列表约束不允许的标签值时。
接下来
6 - Kubernetes 对象状态的指标
kube-state-metrics,一个生成和公开集群层面指标的插件代理。
Kubernetes API 中 Kubernetes 对象的状态可以被公开为指标。
一个名为 kube-state-metrics
的插件代理可以连接到 Kubernetes API 服务器并公开一个 HTTP 端点,提供集群中各个对象的状态所生成的指标。
此代理公开了关于对象状态的各种信息,如标签和注解、启动和终止时间、对象当前所处的状态或阶段。
例如,针对运行在 Pod 中的容器会创建一个 kube_pod_container_info 指标。
其中包括容器的名称、所属的 Pod 的名称、Pod 所在的命名空间 、
容器镜像的名称、镜像的 ID、容器规约中的镜像名称、运行中容器的 ID 和用作标签的 Pod ID。
🛇 本条目指向第三方项目或产品,而该项目(产品)不是 Kubernetes 的一部分。
更多信息 有能力(例如通过 Prometheus)抓取 kube-state-metrics 端点的外部组件现在可用于实现以下使用场景。
示例:使用来自 kube-state-metrics 的指标查询集群状态
通过 kube-state-metrics 生成的系列指标有助于进一步洞察集群,因为这些指标可用于查询。
如果你使用 Prometheus 或其他采用相同查询语言的工具,则以下 PromQL 查询将返回未就绪的 Pod 数:
count(kube_pod_status_ready{condition="false"}) by (namespace, pod)
示例:基于 kube-state-metrics 发出警报
kube-state-metrics 生成的指标还允许在集群中出现问题时发出警报。
如果你使用 Prometheus 或类似采用相同警报规则语言的工具,若有某些 Pod 处于 Terminating 状态超过 5 分钟,将触发以下警报:
groups :
name : Pod state
rules :
- alert : PodsBlockedInTerminatingState
expr : count(kube_pod_deletion_timestamp) by (namespace, pod) * count(kube_pod_status_reason{reason="NodeLost"} == 0) by (namespace, pod) > 0
for : 5m
labels :
severity : page
annotations :
summary : Pod {{$labels.namespace}}/{{$labels.pod}} blocked in Terminating state.
7 - 系统日志
系统组件的日志记录集群中发生的事件,这对于调试非常有用。
你可以配置日志的精细度,以展示更多或更少的细节。
日志可以是粗粒度的,如只显示组件内的错误,
也可以是细粒度的,如显示事件的每一个跟踪步骤(比如 HTTP 访问日志、pod 状态更新、控制器动作或调度器决策)。
警告:
与此处描述的命令行标志不同,日志输出本身不属于 Kubernetes API 的稳定性保证范围:
单个日志条目及其格式可能会在不同版本之间发生变化!
Klog
klog 是 Kubernetes 的日志库。
klog
为 Kubernetes 系统组件生成日志消息。
Kubernetes 正在进行简化其组件日志的努力。下面的 klog 命令行参数从 Kubernetes v1.23
开始已被废弃 ,
在 Kubernetes v1.26 中被移除:
--add-dir-header--alsologtostderr--log-backtrace-at--log-dir--log-file--log-file-max-size--logtostderr--one-output--skip-headers--skip-log-headers--stderrthreshold
输出总会被写到标准错误输出(stderr)之上,无论输出格式如何。
对输出的重定向将由调用 Kubernetes 组件的软件来处理。
这一软件可以是 POSIX Shell 或者类似 systemd 这样的工具。
在某些场合下,例如对于无发行主体的(distroless)容器或者 Windows 系统服务,
这些替代方案都是不存在的。那么你可以使用
kube-log-runner/go-runner,而在服务器和节点的发行版本库中,称作 kube-log-runner。
下表展示的是 kube-log-runner 调用与 Shell 重定向之间的对应关系:
用法
POSIX Shell(例如 Bash)
kube-log-runner <options> <cmd>
合并 stderr 与 stdout,写出到 stdout
2>&1kube-log-runner(默认行为 )
将 stderr 与 stdout 重定向到日志文件
1>>/tmp/log 2>&1kube-log-runner -log-file=/tmp/log
输出到 stdout 并复制到日志文件中
2>&1 | tee -a /tmp/logkube-log-runner -log-file=/tmp/log -also-stdout
仅将 stdout 重定向到日志
>/tmp/logkube-log-runner -log-file=/tmp/log -redirect-stderr=false
klog 输出
传统的 klog 原生格式示例:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
消息字符串可能包含换行符:
I1025 00:15:15.525108 1 example.go:79] This is a message
which has a line break.
结构化日志
特性状态:
Kubernetes v1.23 [beta]
警告:
迁移到结构化日志消息是一个正在进行的过程。在此版本中,并非所有日志消息都是结构化的。
解析日志文件时,你也必须要处理非结构化日志消息。
日志格式和值的序列化可能会发生变化。
结构化日志记录旨在日志消息中引入统一结构,以便以编程方式提取信息。
你可以方便地用更小的开销来处理结构化日志。
生成日志消息的代码决定其使用传统的非结构化的 klog 还是结构化的日志。
默认的结构化日志消息是以文本形式呈现的,其格式与传统的 klog 保持向后兼容:
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
示例:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
字符串在输出时会被添加引号。其他数值类型都使用 %+v具体取决于数据本身 。
I1025 00:15:15.525108 1 example.go:116] "Example" data="This is text with a line break\nand \"quotation marks\"." someInt=1 someFloat=0.1 someStruct={StringField: First line,
second line.}
上下文日志
特性状态:
Kubernetes v1.30 [beta]
上下文日志建立在结构化日志之上。
它主要是关于开发人员如何使用日志记录调用:基于该概念的代码将更加灵活,
并且支持在结构化日志 KEP
中描述的额外用例。
如果开发人员在他们的组件中使用额外的函数,比如 WithValues 或 WithName,
那么日志条目将会包含额外的信息,这些信息会被调用者传递给函数。
对于 Kubernetes 1.31,这一特性是由 StructuredLogging
特性门控 所控制的,默认启用。
这个基础设施是在 1.24 中被添加的,并不需要修改组件。
该 component-base/logs/example
$ cd $GOPATH /src/k8s.io/kubernetes/staging/src/k8s.io/component-base/logs/example/cmd/
$ go run . --help
...
--feature-gates mapStringBool A set of key=value pairs that describe feature gates for alpha/experimental features. Options are:
AllAlpha=true|false (ALPHA - default=false)
AllBeta=true|false (BETA - default=false)
ContextualLogging=true|false (BETA - default=true)
$ go run . --feature-gates ContextualLogging = true
...
I0222 15:13:31.645988 197901 example.go:54] "runtime" logger="example.myname" foo="bar" duration="1m0s"
I0222 15:13:31.646007 197901 example.go:55] "another runtime" logger="example" foo="bar" duration="1h0m0s" duration="1m0s"
logger 键和 foo="bar" 会被函数的调用者添加上,
不需修改该函数,它就会记录 runtime 消息和 duration="1m0s" 值。
禁用上下文日志后,WithValues 和 WithName 什么都不会做,
并且会通过调用全局的 klog 日志记录器记录日志。
因此,这些附加信息不再出现在日志输出中:
$ go run . --feature-gates ContextualLogging = false
...
I0222 15:14:40.497333 198174 example.go:54] "runtime" duration="1m0s"
I0222 15:14:40.497346 198174 example.go:55] "another runtime" duration="1h0m0s" duration="1m0s"
特性状态:
Kubernetes v1.19 [alpha]
警告:
JSON 输出并不支持太多标准 klog 参数。对于不受支持的 klog 参数的列表,
请参见命令行工具参考 。
并不是所有日志都保证写成 JSON 格式(例如,在进程启动期间)。
如果你打算解析日志,请确保可以处理非 JSON 格式的日志行。
字段名和 JSON 序列化可能会发生变化。
--logging-format=json 参数将日志格式从 klog 原生格式改为 JSON 格式。
JSON 日志格式示例(美化输出):
{
"ts" : 1580306777.04728 ,
"v" : 4 ,
"msg" : "Pod status updated" ,
"pod" :{
"name" : "nginx-1" ,
"namespace" : "default"
},
"status" : "ready"
}
具有特殊意义的 key:
ts - Unix 时间风格的时间戳(必选项,浮点值)v - 精细度(仅用于 info 级别,不能用于错误信息,整数)err - 错误字符串(可选项,字符串)msg - 消息(必选项,字符串)
当前支持 JSON 格式的组件列表:
日志精细度级别
参数 -v 控制日志的精细度。增大该值会增大日志事件的数量。
减小该值可以减小日志事件的数量。增大精细度会记录更多的不太严重的事件。
精细度设置为 0 时只记录关键(critical)事件。
日志位置
有两种类型的系统组件:运行在容器中的组件和不运行在容器中的组件。例如:
Kubernetes 调度器和 kube-proxy 在容器中运行。
kubelet 和容器运行时 不在容器中运行。
在使用 systemd 的系统中,kubelet 和容器运行时写入 journald。
在别的系统中,日志写入 /var/log 目录下的 .log 文件中。
容器中的系统组件总是绕过默认的日志记录机制,写入 /var/log 目录下的 .log 文件。
与容器日志类似,你应该轮转 /var/log 目录下系统组件日志。
在 kube-up.sh 脚本创建的 Kubernetes 集群中,日志轮转由 logrotate 工具配置。
logrotate 工具,每天或者当日志大于 100MB 时,轮转日志。
日志查询
特性状态:
Kubernetes v1.30 [beta] (enabled by default: false)
为了帮助在节点上调试问题,Kubernetes v1.27 引入了一个特性来查看节点上当前运行服务的日志。
要使用此特性,请确保已为节点启用了 NodeLogQuery
特性门控 ,
且 kubelet 配置选项 enableSystemLogHandler 和 enableSystemLogQuery 均被设置为 true。
在 Linux 上,我们假设可以通过 journald 查看服务日志。
在 Windows 上,我们假设可以在应用日志提供程序中查看服务日志。
在两种操作系统上,都可以通过读取 /var/log/ 内的文件查看日志。
假如你被授权与节点对象交互,你可以在所有节点或只是某个子集上试用此特性。
这里有一个从节点中检索 kubelet 服务日志的例子:
# 从名为 node-1.example 的节点中获取 kubelet 日志
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet"
你也可以获取文件,前提是日志文件位于 kubelet 允许进行日志获取的目录中。
例如你可以从 Linux 节点上的 /var/log 中获取日志。
kubectl get --raw "/api/v1/nodes/<insert-node-name-here>/proxy/logs/?query=/<insert-log-file-name-here>"
kubelet 使用启发方式来检索日志。
如果你还未意识到给定的系统服务正将日志写入到操作系统的原生日志记录程序(例如 journald)
或 /var/log/ 中的日志文件,这会很有帮助。这种启发方式先检查原生的日志记录程序,
如果不可用,则尝试从 /var/log/<servicename>、/var/log/<servicename>.log
或 /var/log/<servicename>/<servicename>.log 中检索第一批日志。
可用选项的完整列表如下:
选项
描述
bootboot 显示来自特定系统引导的消息
patternpattern 通过提供的兼容 PERL 的正则表达式来过滤日志条目
queryquery 是必需的,指定返回日志的服务或文件
sinceTime显示日志的 RFC3339 起始时间戳(包含)
untilTime显示日志的 RFC3339 结束时间戳(包含)
tailLines指定要从日志的末尾检索的行数;默认为获取全部日志
更复杂的查询示例:
# 从名为 node-1.example 且带有单词 "error" 的节点中获取 kubelet 日志
kubectl get --raw "/api/v1/nodes/node-1.example/proxy/logs/?query=kubelet&pattern=error"
接下来
8 - 追踪 Kubernetes 系统组件
特性状态:
Kubernetes v1.27 [beta]
系统组件追踪功能记录各个集群操作的时延信息和这些操作之间的关系。
Kubernetes 组件基于 gRPC 导出器的
OpenTelemetry 协议
发送追踪信息,并用
OpenTelemetry Collector
收集追踪信息,再将其转交给追踪系统的后台。
追踪信息的收集
Kubernetes 组件具有内置的 gRPC 导出器,供 OTLP 导出追踪信息,可以使用 OpenTelemetry Collector,
也可以不使用 OpenTelemetry Collector。
关于收集追踪信息、以及使用收集器的完整指南,可参见
Getting Started with the OpenTelemetry Collector 。
不过,还有一些特定于 Kubernetes 组件的事项值得注意。
默认情况下,Kubernetes 组件使用 gRPC 的 OTLP 导出器来导出追踪信息,将信息写到
IANA OpenTelemetry 端口 。
举例来说,如果收集器以 Kubernetes 组件的边车模式运行,
以下接收器配置会收集 span 信息,并将它们写入到标准输出。
receivers :
otlp :
protocols :
grpc :
exporters :
# 用适合你后端环境的导出器替换此处的导出器
logging :
logLevel : debug
service :
pipelines :
traces :
receivers : [otlp]
exporters : [logging]
要在不使用收集器的情况下直接将追踪信息发送到后端,请在 Kubernetes
追踪配置文件中指定端点字段以及所需的追踪后端地址。
该方法不需要收集器并简化了整体结构。
对于追踪后端标头配置,包括身份验证详细信息,环境变量可以与 OTEL_EXPORTER_OTLP_HEADERS
一起使用,请参阅 OTLP 导出器配置 。
另外,对于 Kubernetes 集群名称、命名空间、Pod 名称等追踪资源属性配置,
环境变量也可以与 OTEL_RESOURCE_ATTRIBUTES 配合使用,请参见
OTLP Kubernetes 资源 。
组件追踪
kube-apiserver 追踪
kube-apiserver 为传入的 HTTP 请求、传出到 webhook 和 etcd 的请求以及重入的请求生成 span。
由于 kube-apiserver 通常是一个公开的端点,所以它通过出站的请求传播
W3C 追踪上下文 ,
但不使用入站请求的追踪上下文。
在 kube-apiserver 中启用追踪
要启用追踪特性,需要使用 --tracing-config-file=<<配置文件路径> 为
kube-apiserver 提供追踪配置文件。下面是一个示例配置,它为万分之一的请求记录
span,并使用了默认的 OpenTelemetry 端点。
apiVersion : apiserver.config.k8s.io/v1beta1
kind : TracingConfiguration
# 默认值
#endpoint: localhost:4317
samplingRatePerMillion : 100
有关 TracingConfiguration 结构体的更多信息,请参阅
API 服务器配置 API (v1beta1) 。
kubelet 追踪
特性状态:
Kubernetes v1.27 [beta] (enabled by default: true)
kubelet CRI 接口和实施身份验证的 HTTP 服务器被插桩以生成追踪 span。
与 API 服务器一样,端点和采样率是可配置的。
追踪上下文传播也是可以配置的。始终优先采用父 span 的采样决策。
用户所提供的追踪配置采样率将被应用到不带父级的 span。
如果在没有配置端点的情况下启用,将使用默认的 OpenTelemetry Collector
接收器地址 “localhost:4317”。
在 kubelet 中启用追踪
要启用追踪,需应用追踪配置 。
以下是 kubelet 配置的示例代码片段,每 10000 个请求中记录一个请求的
span,并使用默认的 OpenTelemetry 端点:
apiVersion : kubelet.config.k8s.io/v1beta1
kind : KubeletConfiguration
featureGates :
KubeletTracing : true
tracing :
# 默认值
#endpoint: localhost:4317
samplingRatePerMillion : 100
如果 samplingRatePerMillion 被设置为一百万 (1000000),则所有 span 都将被发送到导出器。
Kubernetes v1.31 中的 kubelet 收集与垃圾回收、Pod
同步例程以及每个 gRPC 方法相关的 Span。
kubelet 借助 gRPC 来传播跟踪上下文,以便 CRI-O 和 containerd
这类带有跟踪插桩的容器运行时可以在其导出的 Span 与 kubelet
所提供的跟踪上下文之间建立关联。所得到的跟踪数据会包含 kubelet
与容器运行时 Span 之间的父子链接关系,从而为调试节点问题提供有用的上下文信息。
请注意导出 span 始终会对网络和 CPU 产生少量性能开销,具体取决于系统的总体配置。
如果在启用追踪的集群中出现类似性能问题,可以通过降低 samplingRatePerMillion
或通过移除此配置来彻底禁用追踪来缓解问题。
稳定性
追踪工具仍在积极开发中,未来它会以多种方式发生变化。
这些变化包括:span 名称、附加属性、检测端点等等。
此类特性在达到稳定版本之前,不能保证追踪工具的向后兼容性。
接下来
9 - Kubernetes 中的代理
本文讲述了 Kubernetes 中所使用的代理。
代理
用户在使用 Kubernetes 的过程中可能遇到几种不同的代理(proxy):
kubectl proxy :
运行在用户的桌面或 pod 中
从本机地址到 Kubernetes apiserver 的代理
客户端到代理使用 HTTP 协议
代理到 apiserver 使用 HTTPS 协议
指向 apiserver
添加认证头信息
apiserver proxy :
是一个建立在 apiserver 内部的“堡垒”
将集群外部的用户与集群 IP 相连接,这些 IP 是无法通过其他方式访问的
运行在 apiserver 进程内
客户端到代理使用 HTTPS 协议 (如果配置 apiserver 使用 HTTP 协议,则使用 HTTP 协议)
通过可用信息进行选择,代理到目的地可能使用 HTTP 或 HTTPS 协议
可以用来访问 Node、 Pod 或 Service
当用来访问 Service 时,会进行负载均衡
kube proxy :
在每个节点上运行
代理 UDP、TCP 和 SCTP
不支持 HTTP
提供负载均衡能力
只用来访问 Service
apiserver 之前的代理/负载均衡器:
在不同集群中的存在形式和实现不同 (如 nginx)
位于所有客户端和一个或多个 API 服务器之间
存在多个 API 服务器时,扮演负载均衡器的角色
外部服务的云负载均衡器:
由一些云供应商提供 (如 AWS ELB、Google Cloud Load Balancer)
Kubernetes 服务类型为 LoadBalancer 时自动创建
通常仅支持 UDP/TCP 协议
SCTP 支持取决于云供应商的负载均衡器实现
不同云供应商的云负载均衡器实现不同
Kubernetes 用户通常只需要关心前两种类型的代理,集群管理员通常需要确保后面几种类型的代理设置正确。
请求重定向
代理已经取代重定向功能,重定向功能已被弃用。
10 - API 优先级和公平性
特性状态:
Kubernetes v1.29 [stable]
对于集群管理员来说,控制 Kubernetes API 服务器在过载情况下的行为是一项关键任务。
kube-apiserver
有一些控件(例如:命令行标志 --max-requests-inflight 和 --max-mutating-requests-inflight),
可以限制将要接受的未处理的请求,从而防止过量请求入站,潜在导致 API 服务器崩溃。
但是这些标志不足以保证在高流量期间,最重要的请求仍能被服务器接受。
API 优先级和公平性(APF)是一种替代方案,可提升上述最大并发限制。
APF 以更细粒度的方式对请求进行分类和隔离。
它还引入了空间有限的排队机制,因此在非常短暂的突发情况下,API 服务器不会拒绝任何请求。
通过使用公平排队技术从队列中分发请求,这样,
一个行为不佳的控制器 就不会饿死其他控制器
(即使优先级相同)。
本功能特性在设计上期望其能与标准控制器一起工作得很好;
这类控制器使用通知组件(Informers)获得信息并对 API 请求的失效作出反应,
在处理失效时能够执行指数型回退。其他客户端也以类似方式工作。
注意:
属于 “长时间运行” 类型的某些请求(例如远程命令执行或日志拖尾)不受 API 优先级和公平性过滤器的约束。
如果未启用 APF 特性,即便设置 --max-requests-inflight 标志,该类请求也不受约束。
APF 适用于 watch 请求。当 APF 被禁用时,watch 请求不受 --max-requests-inflight 限制。
启用/禁用 API 优先级和公平性
API 优先级与公平性(APF)特性由命令行标志控制,默认情况下启用。
有关可用 kube-apiserver 命令行参数以及如何启用和禁用的说明,
请参见参数 。
APF 的命令行参数是 "--enable-priority-and-fairness"。
此特性也与某个 API 组 相关:
(a) 稳定的 v1 版本,在 1.29 中引入,默认启用;
(b) v1beta3 版本,默认被启用,在 1.29 中被弃用。
你可以通过添加以下内容来禁用 Beta 版的 v1beta3 API 组:
kube-apiserver \
= flowcontrol.apiserver.k8s.io/v1beta3= false \
# ...其他配置不变
命令行标志 --enable-priority-fairness=false 将彻底禁用 APF 特性。
递归服务器场景 {#Recursive server scenarios}
在递归服务器场景中,必须谨慎使用 API 优先级和公平性。这些场景指的是服务器 A 在处理一个请求时,
会向服务器 B 发出一个辅助请求。服务器 B 可能会进一步向服务器 A 发出辅助请求。
当优先级和公平性控制同时应用于原始请求及某些辅助请求(无论递归多深)时,存在优先级反转和/或死锁的风险。
递归的一个例子是 kube-apiserver 向服务器 B 发出一个准入 Webhook 调用,
而在处理该调用时,服务器 B 进一步向 kube-apiserver 发出一个辅助请求。
另一个递归的例子是,某个 APIService 对象指示 kube-apiserver
将某个 API 组的请求委托给自定义的外部服务器 B(这被称为"聚合")。
当原始请求被确定为属于某个特定优先级别时,将辅助请求分类为更高的优先级别是一个可行的解决方案。
当原始请求可能属于任何优先级时,辅助受控请求必须免受优先级和公平性限制。
一种实现方法是使用下文中讨论的配置分类和处理的对象。
另一种方法是采用前面提到的技术,在服务器 B 上完全禁用优先级和公平性。第三种方法是,
当服务器 B 不是 kube-apiserver 时,最简单的做法是在服务器 B 的代码中禁用优先级和公平性。
概念
APF 特性包含几个不同的功能。
传入的请求通过 FlowSchema 按照其属性分类,并分配优先级。
每个优先级维护自定义的并发限制,加强了隔离度,这样不同优先级的请求,就不会相互饿死。
在同一个优先级内,公平排队算法可以防止来自不同 流(Flow) 的请求相互饿死。
该算法将请求排队,通过排队机制,防止在平均负载较低时,通信量突增而导致请求失败。
优先级
如果未启用 APF,API 服务器中的整体并发量将受到 kube-apiserver 的参数
--max-requests-inflight 和 --max-mutating-requests-inflight 的限制。
启用 APF 后,将对这些参数定义的并发限制进行求和,然后将总和分配到一组可配置的 优先级 中。
每个传入的请求都会分配一个优先级;每个优先级都有各自的限制,设定特定限制允许分发的并发请求数。
例如,默认配置包括针对领导者选举请求、内置控制器请求和 Pod 请求都单独设置优先级。
这表示即使异常的 Pod 向 API 服务器发送大量请求,也无法阻止领导者选举或内置控制器的操作执行成功。
优先级的并发限制会被定期调整,允许利用率较低的优先级将并发度临时借给利用率很高的优先级。
这些限制基于一个优先级可以借出多少个并发度以及可以借用多少个并发度的额定限制和界限,
所有这些均源自下述配置对象。
请求占用的席位
上述并发管理的描述是基线情况。各个请求具有不同的持续时间,
但在与一个优先级的并发限制进行比较时,这些请求在任何给定时刻都以同等方式进行计数。
在这个基线场景中,每个请求占用一个并发单位。
我们用 “席位(Seat)” 一词来表示一个并发单位,其灵感来自火车或飞机上每位乘客占用一个固定座位的供应方式。
但有些请求所占用的席位不止一个。有些请求是服务器预估将返回大量对象的 list 请求。
我们发现这类请求会给服务器带来异常沉重的负担。
出于这个原因,服务器估算将返回的对象数量,并认为请求所占用的席位数与估算得到的数量成正比。
watch 请求的执行时间调整
APF 管理 watch 请求,但这需要考量基线行为之外的一些情况。
第一个关注点是如何判定 watch 请求的席位占用时长。
取决于请求参数不同,对 watch 请求的响应可能以针对所有预先存在的对象 create 通知开头,也可能不这样。
一旦最初的突发通知(如果有)结束,APF 将认为 watch 请求已经用完其席位。
每当向服务器通知创建/更新/删除一个对象时,正常通知都会以并发突发的方式发送到所有相关的 watch 响应流。
为此,APF 认为每个写入请求都会在实际写入完成后花费一些额外的时间来占用席位。
服务器估算要发送的通知数量,并调整写入请求的席位数以及包含这些额外工作后的席位占用时间。
排队
即使在同一优先级内,也可能存在大量不同的流量源。
在过载情况下,防止一个请求流饿死其他流是非常有价值的
(尤其是在一个较为常见的场景中,一个有故障的客户端会疯狂地向 kube-apiserver 发送请求,
理想情况下,这个有故障的客户端不应对其他客户端产生太大的影响)。
公平排队算法在处理具有相同优先级的请求时,实现了上述场景。
每个请求都被分配到某个 流(Flow) 中,该 流 由对应的 FlowSchema 的名字加上一个
流区分项(Flow Distinguisher) 来标识。
这里的流区分项可以是发出请求的用户、目标资源的名字空间或什么都不是。
系统尝试为不同流中具有相同优先级的请求赋予近似相等的权重。
要启用对不同实例的不同处理方式,多实例的控制器要分别用不同的用户名来执行身份认证。
将请求划分到流中之后,APF 功能将请求分配到队列中。
分配时使用一种称为混洗分片(Shuffle-Sharding) 的技术。
该技术可以相对有效地利用队列隔离低强度流与高强度流。
排队算法的细节可针对每个优先等级进行调整,并允许管理员在内存占用、
公平性(当总流量超标时,各个独立的流将都会取得进展)、
突发流量的容忍度以及排队引发的额外延迟之间进行权衡。
豁免请求
某些特别重要的请求不受制于此特性施加的任何限制。
这些豁免可防止不当的流控配置完全禁用 API 服务器。
资源
流控 API 涉及两种资源。
PriorityLevelConfiguration
定义可用的优先级和可处理的并发预算量,还可以微调排队行为。
FlowSchema
用于对每个入站请求进行分类,并与一个 PriorityLevelConfiguration 相匹配。
PriorityLevelConfiguration
一个 PriorityLevelConfiguration 表示单个优先级。每个 PriorityLevelConfiguration
对未完成的请求数有各自的限制,对排队中的请求数也有限制。
PriorityLevelConfiguration 的额定并发限制不是指定请求绝对数量,而是以“额定并发份额”的形式指定。
API 服务器的总并发量限制通过这些份额按例分配到现有 PriorityLevelConfiguration 中,
为每个级别按照数量赋予其额定限制。
集群管理员可以更改 --max-requests-inflight (或 --max-mutating-requests-inflight)的值,
再重新启动 kube-apiserver 来增加或减小服务器的总流量,
然后所有的 PriorityLevelConfiguration 将看到其最大并发增加(或减少)了相同的比例。
注意:
在 v1beta3 之前的版本中,相关的 PriorityLevelConfiguration
字段被命名为“保证并发份额”而不是“额定并发份额”。此外在 Kubernetes v1.25
及更早的版本中,不存在定期的调整:所实施的始终是额定/保证的限制,不存在调整。
一个优先级可以借出的并发数界限以及可以借用的并发数界限在
PriorityLevelConfiguration 表现该优先级的额定限制。
这些界限值乘以额定限制/100.0 并取整,被解析为绝对席位数量。
某优先级的动态调整并发限制范围被约束在
(a) 其额定限制的下限值减去其可借出的席位和
(b) 其额定限制的上限值加上它可以借用的席位之间。
在每次调整时,通过每个优先级推导得出动态限制,具体过程为回收最近出现需求的所有借出的席位,
然后在刚刚描述的界限内共同公平地响应有关这些优先级最近的席位需求。
注意:
启用 APF 特性时,服务器的总并发限制被设置为 --max-requests-inflight 及
--max-mutating-requests-inflight 之和。变更性和非变更性请求之间不再有任何不同;
如果你想针对某给定资源分别进行处理,请制作单独的 FlowSchema,分别匹配变更性和非变更性的动作。
当入站请求的数量大于分配的 PriorityLevelConfiguration 中允许的并发级别时,
type 字段将确定对额外请求的处理方式。
Reject 类型,表示多余的流量将立即被 HTTP 429(请求过多)错误所拒绝。
Queue 类型,表示对超过阈值的请求进行排队,将使用阈值分片和公平排队技术来平衡请求流之间的进度。
公平排队算法支持通过排队配置对优先级微调。
可以在增强建议 中阅读算法的详细信息,
但总之:
queues 递增能减少不同流之间的冲突概率,但代价是增加了内存使用量。
值为 1 时,会禁用公平排队逻辑,但仍允许请求排队。
queueLengthLimit 递增可以在不丢弃任何请求的情况下支撑更大的突发流量,
但代价是增加了等待时间和内存使用量。
下表显示了有趣的随机分片配置集合,每行显示给定的老鼠(低强度流)
被不同数量的大象挤压(高强度流)的概率。
表来源请参阅: https://play.golang.org/p/Gi0PLgVHiUg
混分切片配置示例
随机分片
队列数
1 头大象
4 头大象
16 头大象
12
32
4.428838398950118e-09
0.11431348830099144
0.9935089607656024
10
32
1.550093439632541e-08
0.0626479840223545
0.9753101519027554
10
64
6.601827268370426e-12
0.00045571320990370776
0.49999929150089345
9
64
3.6310049976037345e-11
0.00045501212304112273
0.4282314876454858
8
64
2.25929199850899e-10
0.0004886697053040446
0.35935114681123076
8
128
6.994461389026097e-13
3.4055790161620863e-06
0.02746173137155063
7
128
1.0579122850901972e-11
6.960839379258192e-06
0.02406157386340147
7
256
7.597695465552631e-14
6.728547142019406e-08
0.0006709661542533682
6
256
2.7134626662687968e-12
2.9516464018476436e-07
0.0008895654642000348
6
512
4.116062922897309e-14
4.982983350480894e-09
2.26025764343413e-05
6
1024
6.337324016514285e-16
8.09060164312957e-11
4.517408062903668e-07
FlowSchema
FlowSchema 匹配一些入站请求,并将它们分配给优先级。
每个入站请求都会对 FlowSchema 测试是否匹配,
首先从 matchingPrecedence 数值最低的匹配开始,
然后依次进行,直到首个匹配出现。
注意:
对一个请求来说,只有首个匹配的 FlowSchema 才有意义。
如果一个入站请求与多个 FlowSchema 匹配,则将基于逻辑上最高优先级 matchingPrecedence 的请求进行筛选。
如果一个请求匹配多个 FlowSchema 且 matchingPrecedence 的值相同,则按 name 的字典序选择最小,
但是最好不要依赖它,而是确保不存在两个 FlowSchema 具有相同的 matchingPrecedence 值。
当给定的请求与某个 FlowSchema 的 rules 的其中一条匹配,那么就认为该请求与该 FlowSchema 匹配。
判断规则与该请求是否匹配,不仅 要求该条规则的 subjects 字段至少存在一个与该请求相匹配,
而且 要求该条规则的 resourceRules 或 nonResourceRules
(取决于传入请求是针对资源 URL 还是非资源 URL)字段至少存在一个与该请求相匹配。
对于 subjects 中的 name 字段和资源和非资源规则的
verbs、apiGroups、resources、namespaces 和 nonResourceURLs 字段,
可以指定通配符 * 来匹配任意值,从而有效地忽略该字段。
FlowSchema 的 distinguisherMethod.type 字段决定了如何把与该模式匹配的请求分散到各个流中。
可能是 ByUser,在这种情况下,一个请求用户将无法饿死其他容量的用户;
或者是 ByNamespace,在这种情况下,一个名字空间中的资源请求将无法饿死其它名字空间的资源请求;
或者为空(或者可以完全省略 distinguisherMethod),
在这种情况下,与此 FlowSchema 匹配的请求将被视为单个流的一部分。
资源和你的特定环境决定了如何选择正确一个 FlowSchema。
默认值
每个 kube-apiserver 会维护两种类型的 APF 配置对象:强制的(Mandatory)和建议的(Suggested)。
强制的配置对象
有四种强制的配置对象对应内置的守护行为。这里的行为是服务器在还未创建对象之前就具备的行为,
而当这些对象存在时,其规约反映了这类行为。四种强制的对象如下:
强制的 exempt 优先级用于完全不受流控限制的请求:它们总是立刻被分发。
强制的 exempt FlowSchema 把 system:masters 组的所有请求都归入该优先级。
如果合适,你可以定义新的 FlowSchema,将其他请求定向到该优先级。
强制的 catch-all 优先级与强制的 catch-all FlowSchema 结合使用,
以确保每个请求都分类。一般而言,你不应该依赖于 catch-all 的配置,
而应适当地创建自己的 catch-all FlowSchema 和 PriorityLevelConfiguration
(或使用默认安装的 global-default 配置)。
因为这一优先级不是正常场景下要使用的,catch-all 优先级的并发度份额很小,
并且不会对请求进行排队。
建议的配置对象
建议的 FlowSchema 和 PriorityLevelConfiguration 包含合理的默认配置。
你可以修改这些对象或者根据需要创建新的配置对象。如果你的集群可能承受较重负载,
那么你就要考虑哪种配置最合适。
建议的配置把请求分为六个优先级:
node-high 优先级用于来自节点的健康状态更新。
system 优先级用于 system:nodes 组(即 kubelet)的与健康状态更新无关的请求;
kubelet 必须能连上 API 服务器,以便工作负载能够调度到其上。
leader-election 优先级用于内置控制器的领导选举的请求
(特别是来自 kube-system 名字空间中 system:kube-controller-manager 和
system:kube-scheduler 用户和服务账号,针对 endpoints、configmaps 或 leases 的请求)。
将这些请求与其他流量相隔离非常重要,因为领导者选举失败会导致控制器发生故障并重新启动,
这反过来会导致新启动的控制器在同步信息时,流量开销更大。
workload-high 优先级用于内置控制器的其他请求。workload-low 优先级用于来自所有其他服务帐户的请求,通常包括来自 Pod
中运行的控制器的所有请求。global-default 优先级可处理所有其他流量,例如:非特权用户运行的交互式
kubectl 命令。
建议的 FlowSchema 用来将请求导向上述的优先级内,这里不再一一列举。
强制的与建议的配置对象的维护
每个 kube-apiserver 都独立地维护其强制的与建议的配置对象,
这一维护操作既是服务器的初始行为,也是其周期性操作的一部分。
因此,当存在不同版本的服务器时,如果各个服务器对于配置对象中的合适内容有不同意见,
就可能出现抖动。
每个 kube-apiserver 都会对强制的与建议的配置对象执行初始的维护操作,
之后(每分钟)对这些对象执行周期性的维护。
对于强制的配置对象,维护操作包括确保对象存在并且包含合适的规约(如果存在的话)。
服务器会拒绝创建或更新与其守护行为不一致的规约。
对建议的配置对象的维护操作被设计为允许其规约被重载。删除操作是不允许的,
维护操作期间会重建这类配置对象。如果你不需要某个建议的配置对象,
你需要将它放在一边,并让其规约所产生的影响最小化。
对建议的配置对象而言,其维护方面的设计也支持在上线新的 kube-apiserver
时完成自动的迁移动作,即便可能因为当前的服务器集合存在不同的版本而可能造成抖动仍是如此。
对建议的配置对象的维护操作包括基于服务器建议的规约创建对象
(如果对象不存在的话)。反之,如果对象已经存在,维护操作的行为取决于是否
kube-apiserver 或者用户在控制对象。如果 kube-apiserver 在控制对象,
则服务器确保对象的规约与服务器所给的建议匹配,如果用户在控制对象,
对象的规约保持不变。
关于谁在控制对象这个问题,首先要看对象上的 apf.kubernetes.io/autoupdate-spec
注解。如果对象上存在这个注解,并且其取值为true,则 kube-apiserver
在控制该对象。如果存在这个注解,并且其取值为false,则用户在控制对象。
如果这两个条件都不满足,则需要进一步查看对象的 metadata.generation。
如果该值为 1,则 kube-apiserver 控制对象,否则用户控制对象。
这些规则是在 1.22 发行版中引入的,而对 metadata.generation
的考量是为了便于从之前较简单的行为迁移过来。希望控制建议的配置对象的用户应该将对象的
apf.kubernetes.io/autoupdate-spec 注解设置为 false。
对强制的或建议的配置对象的维护操作也包括确保对象上存在 apf.kubernetes.io/autoupdate-spec
这一注解,并且其取值准确地反映了是否 kube-apiserver 在控制着对象。
维护操作还包括删除那些既非强制又非建议的配置,同时注解配置为
apf.kubernetes.io/autoupdate-spec=true 的对象。
健康检查并发豁免
推荐配置没有为本地 kubelet 对 kube-apiserver 执行健康检查的请求进行任何特殊处理
——它们倾向于使用安全端口,但不提供凭据。
在推荐配置中,这些请求将分配 global-default FlowSchema 和 global-default 优先级,
这样其他流量可以排除健康检查。
如果添加以下 FlowSchema,健康检查请求不受速率限制。
注意:
进行此更改后,任何敌对方都可以发送与此 FlowSchema 匹配的任意数量的健康检查请求。
如果你有 Web 流量过滤器或类似的外部安全机制保护集群的 API 服务器免受常规网络流量的侵扰,
则可以配置规则,阻止所有来自集群外部的健康检查请求。
apiVersion : flowcontrol.apiserver.k8s.io/v1
kind : FlowSchema
metadata :
name : health-for-strangers
spec :
matchingPrecedence : 1000
priorityLevelConfiguration :
name : exempt
rules :
- nonResourceRules :
- nonResourceURLs :
- "/healthz"
- "/livez"
- "/readyz"
verbs :
- "*"
subjects :
- kind : Group
group :
name : "system:unauthenticated"
可观察性
指标
说明:
在 Kubernetes v1.20 之前的版本中,标签 flow_schema 和 priority_level
的名称有时被写作 flowSchema 和 priorityLevel,即存在不一致的情况。
如果你在运行 Kubernetes v1.19 或者更早版本,你需要参考你所使用的集群版本对应的文档。
当你开启了 APF 后,kube-apiserver 会暴露额外指标。
监视这些指标有助于判断你的配置是否不当地限制了重要流量,
或者发现可能会损害系统健康的,行为不良的工作负载。
成熟度水平 BETA
apiserver_flowcontrol_dispatched_requests_total 是一个计数器向量,
记录开始执行的请求数量(自服务器启动以来的累积值),
可按 flow_schema 和 priority_level 分解。
apiserver_flowcontrol_current_inqueue_requests 是一个测量向量,
记录排队中的(未执行)请求的瞬时数量,可按 priority_level 和 flow_schema 分解。
apiserver_flowcontrol_current_executing_requests 是一个测量向量,
记录执行中(不在队列中等待)请求的瞬时数量,可按 priority_level 和 flow_schema 分解。
apiserver_flowcontrol_current_executing_seats 是一个测量向量,
记录了按 priority_level 和 flow_schema 细分的瞬时占用席位数量。
apiserver_flowcontrol_request_wait_duration_seconds 是一个直方图向量,
记录了按 flow_schema、priority_level 和 execute 标签细分的请求在队列中等待的时长。
execute 标签表示请求是否已开始执行。
说明:
由于每个 FlowSchema 总会给请求分配 PriorityLevelConfiguration,
因此你可以将一个优先级的所有 FlowSchema 的直方图相加,以得到分配给该优先级的请求的有效直方图。
apiserver_flowcontrol_nominal_limit_seats 是一个测量向量,
记录了每个优先级的额定并发限制。
此值是根据 API 服务器的总并发限制和优先级的配置额定并发份额计算得出的。
成熟度水平 ALPHA
apiserver_current_inqueue_requests 是一个测量向量,
记录最近排队请求数量的高水位线,
由标签 request_kind 分组,标签的值为 mutating 或 readOnly。
这些高水位线表示在最近一秒钟内看到的最大数字。
它们补充说明了老的测量向量 apiserver_current_inflight_requests
(该量保存了最后一个窗口中,正在处理的请求数量的高水位线)。
apiserver_current_inqueue_seats 是一个测量向量,
记录了排队请求中每个请求将占用的最大席位数的总和,
按 flow_schema 和 priority_level 两个标签进行分组。
apiserver_flowcontrol_read_vs_write_current_requests 是一个直方图向量,
在每个纳秒结束时记录请求数量的观察值,可按标签 phase(取值为 waiting 及 executing)
和 request_kind(取值为 mutating 及 readOnly)分解。
每个观察到的值是一个介于 0 和 1 之间的比值,计算方式为请求数除以该请求数的对应限制
(等待的队列长度限制和执行所用的并发限制)。
apiserver_flowcontrol_request_concurrency_in_use 是一个规范向量,
包含占用席位的瞬时数量,可按 priority_level 和 flow_schema 分解。
apiserver_flowcontrol_priority_level_request_utilization 是一个直方图向量,
在每个纳秒结束时记录请求数量的观察值,
可按标签 phase(取值为 waiting 及 executing)和 priority_level 分解。
每个观察到的值是一个介于 0 和 1 之间的比值,计算方式为请求数除以该请求数的对应限制
(等待的队列长度限制和执行所用的并发限制)。
apiserver_flowcontrol_priority_level_seat_utilization 是一个直方图向量,
在每个纳秒结束时记录某个优先级并发度限制利用率的观察值,可按标签 priority_level 分解。
此利用率是一个分数:(占用的席位数)/(并发限制)。
此指标考虑了除 WATCH 之外的所有请求的所有执行阶段(包括写入结束时的正常延迟和额外延迟,
以覆盖相应的通知操作);对于 WATCH 请求,只考虑传递预先存在对象通知的初始阶段。
该向量中的每个直方图也带有 phase: executing(等待阶段没有席位限制)的标签。
apiserver_flowcontrol_request_concurrency_limit 与
apiserver_flowcontrol_nominal_limit_seats 相同。在优先级之间引入并发度借用之前,
此字段始终等于 apiserver_flowcontrol_current_limit_seats
(它过去不作为一个独立的指标存在)。
apiserver_flowcontrol_lower_limit_seats 是一个测量向量,包含每个优先级的动态并发度限制的下限。
apiserver_flowcontrol_upper_limit_seats 是一个测量向量,包含每个优先级的动态并发度限制的上限。
apiserver_flowcontrol_demand_seats 是一个直方图向量,
统计每纳秒结束时每个优先级的(席位需求)/(额定并发限制)比率的观察值。
某优先级的席位需求是针对排队的请求和初始执行阶段的请求,在请求的初始和最终执行阶段占用的最大席位数之和。
apiserver_flowcontrol_demand_seats_high_watermark 是一个测量向量,
为每个优先级包含了上一个并发度借用调整期间所观察到的最大席位需求。
apiserver_flowcontrol_demand_seats_average 是一个测量向量,
为每个优先级包含了上一个并发度借用调整期间所观察到的时间加权平均席位需求。
apiserver_flowcontrol_demand_seats_stdev 是一个测量向量,
为每个优先级包含了上一个并发度借用调整期间所观察到的席位需求的时间加权总标准偏差。
apiserver_flowcontrol_demand_seats_smoothed 是一个测量向量,
为每个优先级包含了上一个并发度调整期间确定的平滑包络席位需求。
apiserver_flowcontrol_target_seats 是一个测量向量,
包含每个优先级触发借用分配问题的并发度目标值。
apiserver_flowcontrol_seat_fair_frac 是一个测量向量,
包含了上一个借用调整期间确定的公平分配比例。
apiserver_flowcontrol_current_limit_seats 是一个测量向量,
包含每个优先级的上一次调整期间得出的动态并发限制。
apiserver_flowcontrol_request_execution_seconds 是一个直方图向量,
记录请求实际执行需要花费的时间,
可按标签 flow_schema 和 priority_level 分解。
apiserver_flowcontrol_watch_count_samples 是一个直方图向量,
记录给定写的相关活动 WATCH 请求数量,
可按标签 flow_schema 和 priority_level 分解。
apiserver_flowcontrol_work_estimated_seats 是一个直方图向量,
记录与估计席位(最初阶段和最后阶段的最多人数)相关联的请求数量,
可按标签 flow_schema 和 priority_level 分解。
apiserver_flowcontrol_request_dispatch_no_accommodation_total
是一个事件数量的计数器,这些事件在原则上可能导致请求被分派,
但由于并发度不足而没有被分派,
可按标签 flow_schema 和 priority_level 分解。
apiserver_flowcontrol_epoch_advance_total 是一个计数器向量,
记录了将优先级进度计向后跳跃以避免数值溢出的尝试次数,
按 priority_level 和 success 两个标签进行分组。
使用 API 优先级和公平性的最佳实践
当某个给定的优先级级别超过其所被允许的并发数时,请求可能会遇到延迟增加,
或以错误 HTTP 429 (Too Many Requests) 的形式被拒绝。
为了避免这些 APF 的副作用,你可以修改你的工作负载或调整你的 APF 设置,确保有足够的席位来处理请求。
要检测请求是否由于 APF 而被拒绝,可以检查以下指标:
apiserver_flowcontrol_rejected_requests_total:
每个 FlowSchema 和 PriorityLevelConfiguration 拒绝的请求总数。
apiserver_flowcontrol_current_inqueue_requests:
每个 FlowSchema 和 PriorityLevelConfiguration 中排队的当前请求数。
apiserver_flowcontrol_request_wait_duration_seconds:请求在队列中等待的延迟时间。
apiserver_flowcontrol_priority_level_seat_utilization:
每个 PriorityLevelConfiguration 的席位利用率。
工作负载修改
为了避免由于 APF 导致请求排队、延迟增加或被拒绝,你可以通过以下方式优化请求:
减少请求执行的速率。在固定时间段内减少请求数量将导致在某一给定时间点需要的席位数更少。
避免同时发出大量消耗较多席位的请求。请求可以被优化为使用更少的席位或降低延迟,
使这些请求占用席位的时间变短。列表请求根据请求期间获取的对象数量可能会占用多个席位。
例如通过使用分页等方式限制列表请求中取回的对象数量,可以在更短时间内使用更少的总席位数。
此外,将列表请求替换为监视请求将需要更低的总并发份额,因为监视请求仅在初始的通知突发阶段占用 1 个席位。
如果在 1.27 及更高版本中使用流式列表,因为集合的整个状态必须以流式传输,
所以监视请求在其初始的通知突发阶段将占用与列表请求相同数量的席位。
请注意,在这两种情况下,监视请求在此初始阶段之后将不再保留任何席位。
请注意,由于请求数量增加或现有请求的延迟增加,APF 可能会导致请求排队或被拒绝。
例如,如果通常需要 1 秒执行的请求开始需要 60 秒,由于延迟增加,
请求所占用的席位时间可能超过了正常情况下的时长,APF 将开始拒绝请求。
如果在没有工作负载显著变化的情况下,APF 开始在多个优先级级别上拒绝请求,
则可能存在控制平面性能的潜在问题,而不是工作负载或 APF 设置的问题。
优先级和公平性设置
你还可以修改默认的 FlowSchema 和 PriorityLevelConfiguration 对象,
或创建新的对象来更好地容纳你的工作负载。
APF 设置可以被修改以实现下述目标:
给予高优先级请求更多的席位。
隔离那些非必要或开销大的请求,因为如果与其他流共享,这些请求可能会耗尽所有并发级别。
给予高优先级请求更多的席位
如果有可能,你可以通过提高 max-requests-inflight 和 max-mutating-requests-inflight
参数的值为特定 kube-apiserver 提高所有优先级级别均可用的席位数量。另外,
如果在请求的负载均衡足够好的情况下,水平扩缩 kube-apiserver 实例的数量将提高集群中每个优先级级别的总并发数。
你可以创建一个新的 FlowSchema,在其中引用并发级别更高的 PriorityLevelConfiguration。
这个新的 PriorityLevelConfiguration 可以是现有的级别,也可以是具有自己一组额定并发份额的新级别。
例如,你可以引入一个新的 FlowSchema 来将请求的 PriorityLevelConfiguration
从全局默认值更改为工作负载较低的级别,以增加用户可用的席位数。
创建一个新的 PriorityLevelConfiguration 将减少为现有级别指定的席位数。
请注意,编辑默认的 FlowSchema 或 PriorityLevelConfiguration 需要将
apf.kubernetes.io/autoupdate-spec 注解设置为 false。
你还可以为服务于高优先级请求的 PriorityLevelConfiguration 提高 NominalConcurrencyShares。
此外在 1.26 及更高版本中,你可以为有竞争的优先级级别提高 LendablePercent,以便给定优先级级别可以借用更多的席位。
隔离非关键请求以免饿死其他流
为了进行请求隔离,你可以创建一个 FlowSchema,使其主体与发起这些请求的用户匹配,
或者创建一个与请求内容匹配(对应 resourceRules)的 FlowSchema。
接下来,你可以将该 FlowSchema 映射到一个具有较低席位份额的 PriorityLevelConfiguration。
例如,假设来自 default 名字空间中运行的 Pod 的每个事件列表请求使用 10 个席位,并且执行时间为 1 分钟。
为了防止这些开销大的请求影响使用现有服务账号 FlowSchema 的其他 Pod 的请求,你可以应用以下
FlowSchema 将这些列表调用与其他请求隔离开来。
用于隔离列表事件请求的 FlowSchema 对象示例:
apiVersion : flowcontrol.apiserver.k8s.io/v1
kind : FlowSchema
metadata :
name : list-events-default-service-account
spec :
distinguisherMethod :
type : ByUser
matchingPrecedence : 8000
priorityLevelConfiguration :
name : catch-all
rules :
- resourceRules :
- apiGroups :
- '*'
namespaces :
- default
resources :
- events
verbs :
- list
subjects :
- kind : ServiceAccount
serviceAccount :
name : default
namespace : default
这个 FlowSchema 用于抓取 default 名字空间中默认服务账号所发起的所有事件列表调用。
匹配优先级为 8000,低于现有服务账号 FlowSchema 所用的 9000,因此这些列表事件调用将匹配到
list-events-default-service-account 而不是服务账号。
通用 PriorityLevelConfiguration 用于隔离这些请求。通用优先级级别具有非常小的并发份额,并且不对请求进行排队。
接下来
11 - 安装扩展(Addon)
说明: 本部分链接到提供 Kubernetes 所需功能的第三方项目。Kubernetes 项目作者不负责这些项目。此页面遵循
CNCF 网站指南 ,按字母顺序列出项目。要将项目添加到此列表中,请在提交更改之前阅读
内容指南 。
Add-on 扩展了 Kubernetes 的功能。
本文列举了一些可用的 add-on 以及到它们各自安装说明的链接。该列表并不试图详尽无遗。
联网和网络策略
ACI 通过 Cisco ACI 提供集成的容器网络和安全网络。Antrea 在第 3/4 层执行操作,为 Kubernetes
提供网络连接和安全服务。Antrea 利用 Open vSwitch 作为网络的数据面。
Antrea 是一个沙箱级的 CNCF 项目 。Calico 是一个联网和网络策略供应商。
Calico 支持一套灵活的网络选项,因此你可以根据自己的情况选择最有效的选项,包括非覆盖和覆盖网络,带或不带 BGP。
Calico 使用相同的引擎为主机、Pod 和(如果使用 Istio 和 Envoy)应用程序在服务网格层执行网络策略。Canal
结合 Flannel 和 Calico,提供联网和网络策略。Cilium 是一种网络、可观察性和安全解决方案,具有基于 eBPF 的数据平面。
Cilium 提供了简单的 3 层扁平网络,
能够以原生路由(routing)和覆盖/封装(overlay/encapsulation)模式跨越多个集群,
并且可以使用与网络寻址分离的基于身份的安全模型在 L3 至 L7 上实施网络策略。
Cilium 可以作为 kube-proxy 的替代品;它还提供额外的、可选的可观察性和安全功能。
Cilium 是一个毕业级别的 CNCF 项目 。
CNI-Genie 使 Kubernetes 无缝连接到
Calico、Canal、Flannel 或 Weave 等其中一种 CNI 插件。
CNI-Genie 是一个沙箱级的 CNCF 项目 。Contiv 为各种用例和丰富的策略框架提供可配置的网络
(带 BGP 的原生 L3、带 vxlan 的覆盖、标准 L2 和 Cisco-SDN/ACI)。
Contiv 项目完全开源 。
其安装程序 提供了基于 kubeadm 和非 kubeadm 的安装选项。Contrail 基于
Tungsten Fabric ,是一个开源的多云网络虚拟化和策略管理平台。
Contrail 和 Tungsten Fabric 与业务流程系统(例如 Kubernetes、OpenShift、OpenStack 和 Mesos)集成在一起,
为虚拟机、容器或 Pod 以及裸机工作负载提供了隔离模式。
Flannel
是一个可以用于 Kubernetes 的 overlay 网络提供者。Gateway API 是一个由
SIG Network 社区管理的开源项目,
为服务网络建模提供一种富有表达力、可扩展和面向角色的 API。Knitter 是在一个 Kubernetes Pod 中支持多个网络接口的插件。Multus 是一个多插件,
可在 Kubernetes 中提供多种网络支持,以支持所有 CNI 插件(例如 Calico、Cilium、Contiv、Flannel),
而且包含了在 Kubernetes 中基于 SRIOV、DPDK、OVS-DPDK 和 VPP 的工作负载。
OVN-Kubernetes 是一个 Kubernetes 网络驱动,
基于 OVN(Open Virtual Network) 实现,是从 Open vSwitch (OVS)
项目衍生出来的虚拟网络实现。OVN-Kubernetes 为 Kubernetes 提供基于覆盖网络的网络实现,
包括一个基于 OVS 实现的负载均衡器和网络策略。Nodus 是一个基于 OVN 的 CNI 控制器插件,
提供基于云原生的服务功能链 (SFC)。
NSX-T 容器插件(NCP)
提供了 VMware NSX-T 与容器协调器(例如 Kubernetes)之间的集成,以及 NSX-T 与基于容器的
CaaS / PaaS 平台(例如关键容器服务(PKS)和 OpenShift)之间的集成。Nuage
是一个 SDN 平台,可在 Kubernetes Pods 和非 Kubernetes 环境之间提供基于策略的联网,并具有可视化和安全监控。Romana 是一个 Pod 网络的第三层解决方案,并支持
NetworkPolicy API。Spiderpool 为 Kubernetes
提供了下层网络和 RDMA 高速网络解决方案,兼容裸金属、虚拟机和公有云等运行环境。Weave Net
提供在网络分组两端参与工作的联网和网络策略,并且不需要额外的数据库。
服务发现
CoreDNS 是一种灵活的,可扩展的 DNS 服务器,可以
安装 为集群内的 Pod 提供 DNS 服务。
可视化管理
基础设施
插桩
遗留 Add-on
还有一些其它 add-on 归档在已废弃的 cluster/addons 路径中。
维护完善的 add-on 应该被链接到这里。欢迎提出 PR!
12 - 集群自动扩缩容
自动管理集群中的节点以适配需求。
Kubernetes 需要集群中的节点 来运行
Pod 。
这意味着需要为工作负载 Pod 以及 Kubernetes 本身提供容量。
你可以自动调整集群中可用的资源量:节点自动扩缩容 。
你可以更改节点的数量,或者更改节点提供的容量。
第一种方法称为水平扩缩容 ,而第二种方法称为垂直扩缩容 。
Kubernetes 甚至可以为节点提供多维度的自动扩缩容。
手动节点管理
你可以手动管理节点级别的容量,例如你可以配置固定数量的节点;
即使这些节点的制备(搭建、管理和停用过程)是自动化的,你也可以使用这种方法。
本文介绍的是下一步操作,即自动化管理集群中可用的节点容量(CPU、内存和其他节点资源)。
自动水平扩缩容
Cluster Autoscaler
你可以使用 Cluster Autoscaler
自动管理节点的数目规模。Cluster Autoscaler 可以与云驱动或 Kubernetes 的
Cluster API
集成,以完成实际所需的节点管理。
当存在不可调度的 Pod 时,Cluster Autoscaler 会添加节点;
当这些节点为空时,Cluster Autoscaler 会移除节点。
云驱动集成组件
Cluster Autoscaler 的
README
中列举了一些可用的云驱动集成组件。
成本感知多维度扩缩容
Karpenter
Karpenter 支持通过继承了特定云驱动的插件来直接管理节点,
还可以在优化总体成本的同时为你管理节点。
Karpenter 自动启动适合你的集群应用的计算资源。
Karpenter 设计为让你充分利用云资源,快速简单地为 Kubernetes 集群制备计算资源。
Karpenter 工具设计为与云驱动集成,提供 API 驱动的服务器管理,
此工具可以通过 Web API 获取可用服务器的价格信息。
例如,如果你在集群中启动更多 Pod,Karpenter 工具可能会购买一个比你当前使用的节点更大的新节点,
然后在这个新节点投入使用后关闭现有的节点。
云驱动集成组件
说明: 本页面中的条目引用了 Kubernetes 外部的供应商。Kubernetes 项目的开发人员不对这些第三方产品(项目)负责。要将供应商、产品或项目添加到此列表中,请在提交更改之前阅读
内容指南 。
更多信息。 在 Karpenter 的核心与以下云驱动之间,存在可用的集成组件:
Descheduler
Descheduler
可以帮助你将 Pod 集中到少量节点上,以便在集群有空闲容量时帮助自动缩容。
基于集群大小调整工作负载
Cluster Proportional Autoscaler
对于需要基于集群大小进行扩缩容的工作负载(例如 cluster-dns 或其他系统组件),
你可以使用 Cluster Proportional Autoscaler
Cluster Proportional Autoscaler 监视可调度节点和核心的数量,并相应地调整目标工作负载的副本数量。
Cluster Proportional Vertical Autoscaler
如果副本数量应该保持不变,你可以使用
Cluster Proportional Vertical Autoscaler
基于集群大小垂直扩缩你的工作负载。此项目处于 Beta 阶段,托管在 GitHub 上。
Cluster Proportional Autoscaler 扩缩工作负载的副本数量,而 Cluster Proportional Vertical Autoscaler
基于集群中的节点和/或核心数量调整工作负载(例如 Deployment 或 DaemonSet)的资源请求。
接下来
13 - 协调领导者选举
特性状态:
Kubernetes v1.31 [alpha] (enabled by default: false)
Kubernetes 1.31 包含一个 Alpha 特性,
允许控制平面 组件通过协调领导者选举 确定性地选择一个领导者。
这对于在集群升级期间满足 Kubernetes 版本偏差约束非常有用。
目前,唯一内置的选择策略是 OldestEmulationVersion,
此策略会优先选择最低仿真版本作为领导者,其次按二进制版本选择领导者,最后会按创建时间戳选择领导者。
启用协调领导者选举
确保你在启动 API 服务器 时
CoordinatedLeaderElection 特性门控 被启用,
并且 coordination.k8s.io/v1alpha1 API 组被启用。
此操作可以通过设置 --feature-gates="CoordinatedLeaderElection=true"
和 --runtime-config="coordination.k8s.io/v1alpha1=true" 标志来完成。
组件配置
前提是你已启用 CoordinatedLeaderElection 特性门控并且
启用了 coordination.k8s.io/v1alpha1 API 组,
兼容的控制平面组件会自动使用 LeaseCandidate 和 Lease API 根据需要选举领导者。
对于 Kubernetes 1.31,
当特性门控和 API 组被启用时,
两个控制平面组件(kube-controller-manager 和 kube-scheduler)会自动使用协调领导者选举。